Graphics Reference
In-Depth Information
= 130 transcripts. In those cases where the occurrences of the tokens
searched for may be ambiguous, the respective findings were manually
inspected and qualitatively interpreted within their context.
Linguistic structures
The packing/unpacking phase of the
N
= 130 transcripts can be
summarized as follows: We had a total of 8,622 user utterances. When
we performed part of speech (POS) tagging (with a slightly modified
version of STTS
1
) and then counted the varying POS tag patterns, we
found 2,041 different patterns for the 8,622 utterances. The distribution
was strongly skewed (cf. Table 1): A small number of (regular) POS
patterns did cover a significant fraction of utterances.
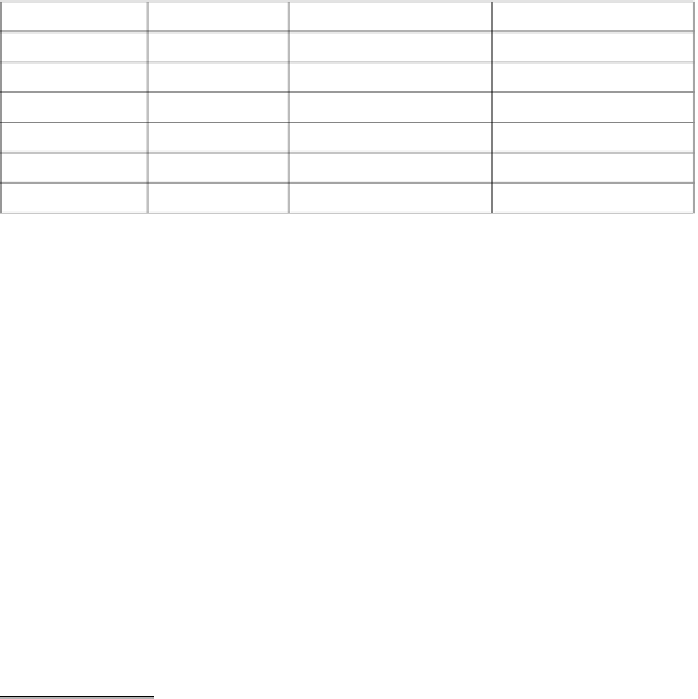
Table 1. Most frequent POS patterns for elliptical structures.
Class
Sem
POS pattern
No. of occurrences
E
P
ART NN
1,020
E
P
CARD NN
657
E
P
NN
537
E
C
ADJ NN
355
E
C
ADJ, ADV
349
E
C
NN
148
When classifying the POS tag sequences, we distinguished four
categories: full sentences and sentence-like structures (S; with an
obligatory verb), elliptical constructs without a verb (E), telegrammatic
constructs (T, cf. above) and meaningful pauses, i.e. user utterances
that more or less consisted of interjections only (DP). In descending
order of occurrences we had the following counts:
5,069 user utterances or 58.79% (realized with 223 patterns) were
classified as E,
807 user utterances or 9.36% (realized with 135 patterns) as S,
551 user utterances or 6.39% (realized with 21 patterns) as T, and
finally
178 user utterances or 2.06% (realized with 8 patterns) as DP.
At the time of writing, 2,017 utterances that were realized by 1,654
different patterns could not be uniquely classified. In many cases, this
was due to the typical phenomena of spontaneous spoken language,
e.g. repairs, restarts, and the use of interjections.
1
www.ims.uni-stuttgart.de/projekte/corplex/TagSets/stts-table.html
Search WWH ::

Custom Search