Graphics Reference
In-Depth Information
decider doesn't signal Other-Giving-Turn, essentially canceling the
plan to start speaking (see Figure 5). This leads to a better reward,
since no overlapping speech occurs. If he starts talking just after the
STW closes, after the decider signals Other-Gives-Turn, overlapping
speech will likely occur (keep in mind that, due to processing time,
once a decision has been made it can take time before it is actually
executed), leading to negative reinforcement for this size of STW given
to the particular prosodic information observed.
This learning strategy is based on the assumption that both
agents want to take turns cooperatively (“politely”) and efficiently.
We have already begun expanding the system to be able to interrupt
dynamically and deliberately—i.e. be “rude”—and the ability to switch
back to being polite at any time, without destroying the learned data.
This research will be discussed at a later date.
5. Quantitative Evaluation of Learning
We will look at system performance across three dependent measures:
•
The system's ability to select an appropriate STW. Given a silence
in the user 's speech, the selection of an STW is based on the type
of prosody pattern perceived right before the silence. If turn-
giving indicators are perceivable to the system, we should find
clear variations in STW lengths based on the pattern perceived. If
no evidence of turn-giving is detected by the system, we should
find an even distribution of STW size between patterns.
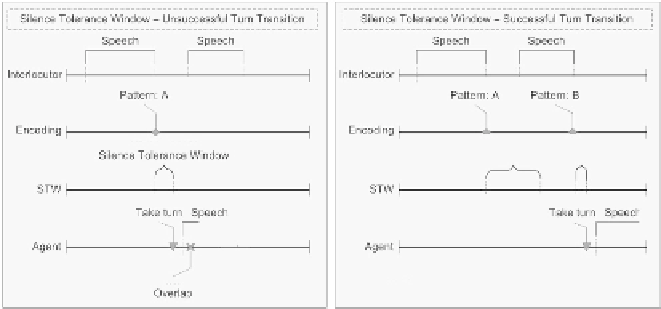
Figure 5.
The interlocutor's speech is analyzed in real-time; as soon as a silence is detected
the prosody preceding the silence is decoded. The system makes a prediction by selecting
an STW, based on the prosody pattern perceived in the interlocutor. This window is a
prediction of the shortest safe duration to wait before taking turn: A window that is too
short will probably result in overlapping speech while a window that is too large may cause
unnecessary or unwanted silences.

Search WWH ::

Custom Search