Java Reference
In-Depth Information
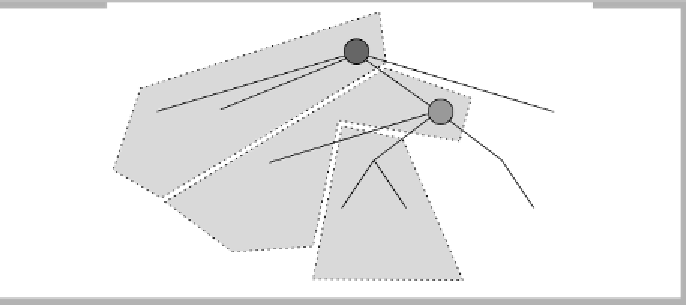
figure 24.10
After the recursive call
from
D
returns, we
merge the set
anchored by
D
into
the set anchored by
C
and then compute
all
NCA(
C, v
)
for
nodes
v
marked prior
to completing
C
's
recursive call.
A
B
C
D
changed from
D
to
C
. The new situation is shown in Figure 24.10. Thus we
need to merge the two equivalence classes into one. At any point, we can
obtain the anchor for a vertex
v
by a call to a disjoint set
find
. Because
find
returns a set number, we use an array
anchor
to store the anchor node corre-
sponding to a particular set.
A pseudocode implementation of the NCA algorithm is shown in
Figure 24.11. As mentioned earlier in the chapter, the
find
operation gener-
ally is based on the assumption that elements of the set are 0, 1, , so
we store a preorder number in each tree node in a preprocessing step that
computes the size of the tree. An object-oriented approach might attempt to
incorporate a mapping into the
find
, but we do not do so. We also assume that
we have an array of lists in which to store the NCA requests; that is, list
i
stores the requests for tree node
i
. With those details taken care of, the code is
remarkably short.
When a node
u
is first visited, it becomes the anchor of itself, as in line 18
of Figure 24.11. It then recursively processes its children
v
by making the call
at line 23. After each recursive call returns, the subtree is combined into
u
's
current equivalence class and we ensure that the anchor is updated at lines 24
and 25. When all the children have been processed recursively, we can mark
u
as processed at line 29 and finish by checking all NCA requests involving
u
at
lines 30 to 33.
2
The pseudocode is
compact.
…
N
1,
-
2. Strictly speaking,
u
should be marked at the last statement, but marking it earlier handles the
annoying request NCA(
u
,
u
).





Search WWH ::

Custom Search