Database Reference
In-Depth Information
SELECT n name, SUM(l extendedprice*(1-l discount)) AS revenue
FROM customers, orders, lineitem, supplier, nation, region
WHERE c custkey = o custkey
AND o orderkey = l orderkey
AND l suppkey = s suppkey
AND c nationkey = s nationkey
AND s nationkey = n nationkey
AND n regionkey = r regionkey
AND r name = 'AMERICA'
AND o orderdate BETWEEN '1997-01-01' AND dateadd(YY, 1, '1997-01-01')
GROUP BY n name
ORDER BY revenue DESC
FIGURE 3.1
A synthetic query of moderate complexity.
such narrow indexes to seek the relevant tuples, followed by RID lookups to
the primary index and a final filter for the remaining predicates, can still be
better than having no indexes. Of course, combinations of all these indexes
result in complex trade-offs between required storage and the resulting query
performance.
To finish our example, suppose that we add an update query to our work-
load:
Q4 = UPDATE R
SETB=B+1
WHERE 10<C<20
In this case, every index that contains column
B
needs to be updated by
Q4
. Obtaining the best set of indexes for a workload consisting of
{
Q2, Q3,
Q4
}
requires a nontrivial analysis and understanding of the cost model, search
space, and other optimizer internals.
To top it all, so far we have considered very simple single-table queries. Real
queries are rarely so well behaved. For instance, Figure 3.1 shows query 5 from
the synthetic
TPC-H
benchmark, which models queries of medium complexity
in a decision support scenario. This query contains joins among six tables,
predicates that involve built-in functions like
dateadd
, group-by clauses, and
arithmetic operations in the
SELECT
clause. Obtaining index recommendations
for workloads consisting of several such queries is very complex. We calculated
the number of possible indexes that, if present, would be considered in a
candidate plan by the query optimizer. Figure 3.2 shows these counts for each
table in the database and different workloads. For instance, if we consider only
query 5, there are around 80 possible indexes that are relevant overall. While
this number might seem small, our task is to pick a good
subset
of these 80
indexes, which already introduces a combinatorial explosion in the number
of possible index configurations. In any case, repeating the same experiment
for the first five queries in the benchmark results in over 50,000 candidate
indexes. Finally, the full 22-query workload results in over a billion candidate


















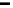




Search WWH ::

Custom Search