Database Reference
In-Depth Information
20
19
17
13
10
5
0123456789
(d)
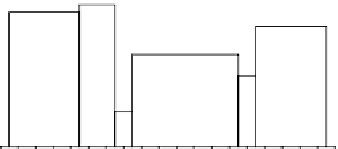
Max-diff
histogram.
10 11 12 13 14 15 16 17 18 19
19
18
17
11
10
9
0123456789
(e)
End-biased
histogram.
10 11 12 13 14 15 16 17 18 19
FIGURE 2.5
(Continued).
In absence of multidimensional statistics, we also assume that predicates in
different columns are independent. Using these assumptions, there are simple
procedures to estimate the number of output tuples for each operator. For
instance, to estimate the cardinality of single-table range predicates we use
interpolation over the histogram buckets. Join estimation requires that we
combine information of two histograms, and involves aligning buckets and
relying on simplifying assumptions on data distributions. Group-by queries
leverage the number of distinct values, stored either globally at the column
level or inside each histogram bucket.
2.3 Enumeration Strategy
An enumeration algorithm must pick an ecient execution plan for an input
query by effectively exploring the search space. A software engineering consid-
eration while designing an enumeration algorithm is to allow it to gracefully
adapt to changes in the search space or cost model. Optimization architec-
tures built with this paradigm are called
extensible optimizers
. Building an
extensible optimize involves not just designing a better enumeration algorithm
but also providing an infrastructure for evolution of the optimizer design. In
this section we focus on three representative examples of such extensible opti-
mizers. We first discuss System-R, an elegant approach that helped fuel much
of the subsequent work in optimization. Then, we briefly review Starburst,












Search WWH ::

Custom Search