Hardware Reference
In-Depth Information
The Core i7's Sandy Bridge Pipeline
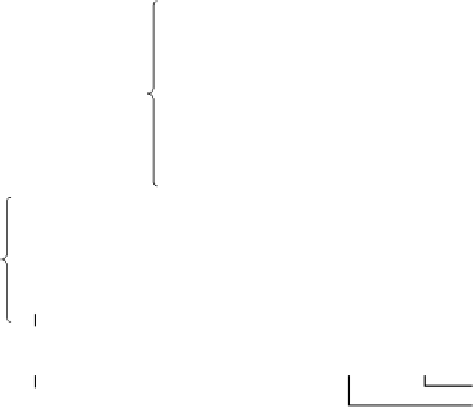
Figure 4-47 is a simplified version of the Sandy Bridge microarchitecture
showing the pipeline. At the top is the front end, whose job is to fetch instructions
from memory and prepare them for execution. The front end is fed new x86 in-
structions from the L1 instruction cache. It decodes them into micro-ops for stor-
age in the micro-op cache, which holds approximately 1.5K micro-ops. A micro-
op cache of this size performs comparably to a 6-KB conventional L0 cache. The
micro-op cache holds groups of six micro-ops in a single trace line. For longer se-
quences of micro-ops, multiple trace lines can be linked together.
Level 1
inst cache
Branch
predictor/
Branch
target
buffer
Front
end
Decode unit
To shared
L3 cache
Micro-op
cache
Level 2
unified
cache
Allocate/Rename unit
Out-
of-
order
control
Non-
memory scheduler
Memory
scheduler
ALU 1
ALU 2
ALU 3
Store
Load 1
Load 2
Level 1
data
cache
Retirement unit
Figure 4-47.
A simplified view of the Core i7 data path.
If the decode unit hits a conditional branch, it looks up its predicted direction
in the
Branch Predictor
. The branch predictor contains the history of branches
encountered in the past, and it uses this history to guess whether or not a condi-
tional branch is going to be taken the next time it is encountered. This is where the
top-secret algorithm is used.
If the branch instruction is not in the table, static prediction is used. A back-
ward branch is assumed to be part of a loop and assumed to be taken. The accu-
racy of these static predictions is extremely high. A forward branch is assumed to
be part of an
if
statement and is assumed not to be taken. The accuracy of these
static predictions is much lower than that of the backward branches.