Graphics Reference
In-Depth Information
(a)
(b)
(c)
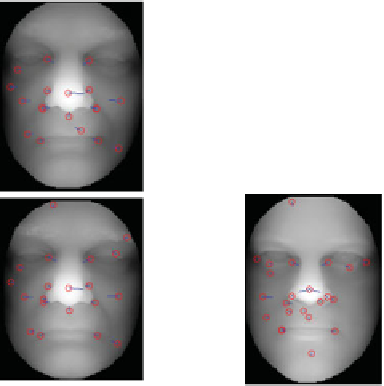
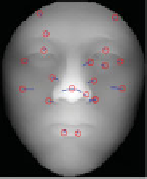
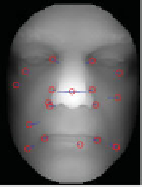
Figure 5.9
Each column shows three depth images of the same individual. It can be noticed that a large
part of the keypoints are repeatably identified at the same neighborhoods for the same individual
spikes were removed using median filtering in the
z
-coordinate, holes were filled using cubic
interpolation, and the 3D scans were re-sampled on an uniform square grid at 1 mm resolution.
Figure 5.9 shows the depth images derived from the 3D face scans of three different subjects.
For the detected keypoints, the SIFT
descriptors
are computed. The properties of the SIFT
descriptor make it capable to provide a compact and powerful local representation of the depth
image and, as a consequence, of the face surface. Because the localization of SIFT keypoints
only depends on the geometry of the face surface, these keypoints are not guaranteed to
correspond to specific meaningful landmarks on the face. For the same reason, the detection
of keypoints on two face scans of the same individual should yield to the identification of
the same points on the face, unless the shape of the face is altered by major occlusions or
non-neutral facial expressions. As an example, Figure 5.9 shows the keypoints identified on
the depth images of three subjects.
An important measure to validate the effectiveness of the extracted keypoints is represented
by their
repeatability
. This can be evaluated using the approach in Mian et al. (2008). In
this solution, the correspondence of the location of keypoints detected in two face scans is
measured by considering ICP registration: The 3D faces belonging to the same individual are
automatically registered and the errors between the nearest neighbors of their keypoints (one
from each face) are recorded.