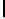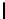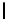Graphics Reference
In-Depth Information
// Loop over time points in data
for
(
int
t
=0;
t
<
DATA_T
;
t
++)
{
// Reset filter response for current volume
cudaMemset
(
d_FR
,0,
DATA_W
DATA_H
DATA_D
sizeof
(
float
));
// Loop over time points in f i l t e r
for
(
int
tt
=
FILTER_T
−
1;
tt
>
=0;
tt
−−
)
{
// Loop over s l ic es in f i l t e r
for
(
int
zz
=
FILTER_D
−
)
{
// Copy current filter coefficients to constant memory
CopyFilterCoefficients
(
zz
,
tt
);
1;
zz
>
=0;
zz
−−
// Perform 2D convolution and
// accumulate the filter responses inside the kernel ,
// launch kernel for several slices simultaneously
Convolution_2D_Shared
<<<
dG
,
dB
>>>
(
d_FR
);
}
}
}
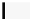
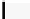
Listing 5.4.
Host code for non-separable 4D convolution, by performing non-separable
2D convolution on the GPU and accumulating the filter responses inside the kernel (
dG
stands for
dimGrid
,
dB
stands for
dimBlock
,and
FR
stands for filter responses). The
CPU takes care of three
for
loops and the GPU five
for
loops.
convolution kernel, the filter responses are accumulated inside the kernel. Before
each 2D convolution is started, the corresponding 2D values of the 4D filter are
copied to constant memory.
A small problem remains; for a 4D dataset of size 128
×
128
×
128
×
128, the
2D convolution will be applied to images of size 128
48 valid
filter responses are calculated per thread block, only five thread blocks will be
launched. The Nvidia GTX 680 has eight MPs and each MP can concurrently
handle two thread blocks with 1024 threads each. At least 16 thread blocks are
thus required to achieve full occupancy. To solve this problem one can launch the
2D convolution for all slices simultaneously, by using 3D thread blocks, to increase
the number of thread blocks and thereby the occupancy. This removes one loop
on the CPU, such that three loops are taken care of by the CPU and five by the
GPU. As some of the slices in the filter response will be invalid due to border
effects, some additional time can be saved by only performing the convolution
for the valid slices. The host code for non-separable 4D convolution is given in
Listing 5.4 and the complete code is available in the github repository.
×
128 pixels. If 80
×
5.8 Non-separable 3D Convolution, Revisited
Now that an implementation for non-separable 4D convolution has been pro-
vided, 3D convolution is very easy. The host code is given in Listing 5.5 and