Graphics Reference
In-Depth Information
__global__
void
Convolution_2D_Texture
(
float
Filter_Response
,
int
DATA_W
,
int
DATA_H
)
{
int
x
=
blockIdx
.
x
blockDim
.
x
+
threadIdx
.
x
;
int
y
=
blockIdx
.
y
blockDim
.
y
+
threadIdx
.
y
;
if
(
x
>
=
DATA_W
||
y
>
=
DATA_H
)
return
;
float
sum
=0.0
f
;
float
y_off
=
−
(
FILTER_H
−
1)/2 + 0.5
f
;
for
(
int
f_y
=
FILTER_H
−
1;
f_y
>
=0;
f_y
−−
)
{
float
x_off
=
−
(
FILTER_W
−
1)/2 + 0.5
f
;
for
(
int
f_x
=
FILTER_W
−
1;
f_x
>
=0;
f_x
−−
)
{
sum
+=
tex2D
(
texture
,
x
+
x_off
,
y
+
y_off
)
c_Filter
[
f_y
][
f_x
];
x_off
+= 1 . 0
f
;
y_off
+= 1 . 0
f
;
}
Filter_Response
[
Get2DIndex
(
x
,
y
,
DATA_W
)] =
sum
;
}
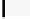
Listing 5.1.
Non-separable 2D convolution using texture memory: each thread calculates
the filter response for one pixel. The filter kernel is stored in cached constant memory
and the image is stored in cached texture memory. If the filter size is known at compile
time, the inner loop can be unrolled by the compiler. The addition of 0.5 to each
coordinate is because the original pixel values for textures are actually stored between
the integer coordinates.
obtain high performance, it is also important to take advantage of the fact that
filter responses for neighboring pixels are calculated from a largely overlapping
set of pixels. We will begin with a CUDA implementation for non-separable 2D
convolution that uses texture memory, as the texture memory cache can speed
up local reads. Threads needing pixel values already accessed by other threads
can thus read the values from the fast cache located at each multiprocessor (MP),
rather than from the slow global memory. The filter kernel is put in the constant
memory (64 KB) as it is used by all the threads. For Nvidia GPUs the constant
memory cache is 8 KB per MP, and 2D filters can thus easily reside in the fast
on-chip cache during the whole execution. The device code for texture-based 2D
convolution is given in Listing 5.1.
The main problem with using texture memory is that such an implemen-
tation is limited by the memory bandwidth, rather than by the computational
performance. A better idea is to instead take advantage of the shared memory
available at each MP, which makes it possible for the threads in a thread block to
cooperate very eciently. Nvidia GPUs from the Fermi and Kepler architectures