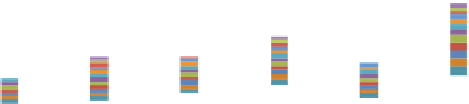Graphics Reference
In-Depth Information
1.6
1.4
1.2
1
0.8
0.6
0.4
0.2
0
(a)
(b)
(a)
(b)
(a)
(b)
(a)
(b)
(a)
(b)
(a)
(b)
Scene 1
Scene 2
Scene 3
Scene 4
Scene 5
Scene 6
Figure 4.7.
Time to solve constraints once in benchmarks using (a) the global and (b) the
two-level constraint solvers. The plots show estimated time for the two-level constraint
solver. Each color corresponds to a single-kernel execution. The global constraint solver
requires several kernel executions, but the two-level constraint solver requires only four
kernel executions. This graph plots the estimated computation time for the two-level
constraint solver.
a group. Thus, batching for scene 6 takes longer than for other scenes.
A comparison of the computation time for the two-level and the global con-
straint solvers shown in Table 4.1 completely contradicts the expectation dis-
cussed in Section 4.5. For most scenes, the two-level constraint solver outper-
forms the global constraint solver, which needs the CPU for batching. The first
potential explanation for the superior performance is that the number of batches
for the two-level solver is smaller in the test scenes. We counted the number of
batches for solvers for all scenes and confirmed that the total number of batches
for the two-level constraint solver is more than that of the global constraint solver
(Table 4.1).
To get a better understanding of this result, we performed more detailed
analyses on the global constraint solver. The solving time for each batch is
measured in Figure 4.8, and the number of constraints in each batch is counted
in Figure 4.9. Figure 4.9 shows that no batch has more than 8,000 constraint
pairs. The maximum number of concurrent works the GPU can execute is more
than the number of SIMDs times the SIMD lane width: 128
64 = 8
,
192 for the
GPU. Therefore, all constraints in a batch are processed concurrently. Batches
with larger batch indices have constant computation times for all benchmarks;
batches with smaller batch indices do not.
Figures 4.8 and 4.9 also show that batches that take longer to solve have
more constraints. Batches with longer execution times, however, should have the
same number of ALU operations per SIMD lane. The difference must come from
memory access latency. As the number of constraint pairs increases, so does the
×