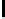Graphics Reference
In-Depth Information
// Integrate and global shape constraints
// One thread computes one vertex
[
numthreads
(
GROUP_SIZE
,1,1)]
void
SimulateHair_A
(
uint GIndex
:
SV_GroupIndex
,
uint3 GId
:
SV_GroupID
,
uint3 DTid
:
SV_DispatchThreadID
)
{
int
offset
=0;
int
strandType
=0;
uint globalStrandIndex
=0;
uint localVertexIndex
=0;
uint indexForSharedMem
=
GIndex
;
uint numOfStrandsPerThreadGroup
=2;
uint maxPossibleVertsInStrand
=(
GROUP_SIZE
/
numOfStrandsPerThreadGroup
);
// If maxPossibleVertsInStrand is 64, one thread group
// computes one hair strand .
// If it is 32, one thread group computes two hair
// strands . Below code takes care of strand and vertex
// indices based on how many strands are computed
// in one thread group.
if
(
GIndex
<
maxPossibleVertsInStrand
)
{
globalStrandIndex
=2
GId
.
x
;
localVertexIndex
=
GIndex
;
}
else
{
globalStrandIndex
=2
GId
.
x
+1;
localVertexIndex
=
GIndex
−
maxPossibleVertsInStrand
;
}
if
(
globalStrandIndex
>
0)
{
offset
=
g_GuideHairVerticesOffsetsSRV
.
Load
(
globalStrandIndex
−
1) ;
strandType
=
g_GuideHairStrandType
.
Load
(
globalStrandIndex
−
1) ;
}
uint globalVertexIndex
=
offset
+
localVertexIndex
;
uint numVerticesInTheStrand
=
g_GuideHairVerticesOffsetsSRV
.
Load
(
globalStrandIndex
)
−
offset
;
// Copy data into shared memory
// Integrate
// Global shaping matching style enforcement
// update global position buffers
}
Listing 1.1.
SimulateHair_A
compute shader kernel.
In case hair simulation should be skipped,
SkipSimulateHair
kernel does this
job. It may be possible to assign 1.0 GSC stiffness but it would waste lots of
computation. The
SkipSimulateHair
kernel applies only the head transform to
vertices and makes the hair do rigid motion.