Graphics Reference
In-Depth Information
14
Postopen
Preopen
12
10
8
6
4
2
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Load Factor
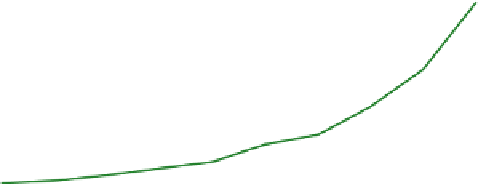
Figure 1.4.
Frame time (ms) versus load-factor for open addressing techniques. Note
the significant performance drop as the load-factor increases.
GeForce Titan, 320.49,
2.5M fragments, average depth complexity: 2.9.
An important benefit of the techniques presented here is that they directly
fit in the graphics pipeline, and do not require switching to a compute API.
Therefore, the Build pass is the same as when rendering without an A-buffer,
augmented with a call to the insertion code. This makes the techniques easy to
integrate in existing pipelines. In addition all approaches require fewer than 30
lines of GLSL code.
Unfortunately implementation on current hardware is not as straightforward
as it could be, for two reasons: First, the hardware available to us does not
natively support
atomicMax
on 64 bits in GLSL (Kepler supports it natively on
CUDA). Fortunately the
atomicMax
64 bits can be emulated via an
atomicCompSwap
instruction in a loop. We estimated the performance impact to approximately
30% by emulating a 32 bits
atomicMax
witha32bits
atomicCompSwap
(on a GeForce
GTX480). The second issue is related to the use of atomic operations in loops,
inside GLSL shaders. The current compiler seems to generate code leading to
race conditions that prevent the loops from operating properly. Our current
implementation circumvents this by inserting additional atomic operations having
no effect on the algorithm result. This, however, incurs in some algorithms a
penalty that is dicult to quantify.
1.7 Experimental Comparisons
We now compare each of the four versions and discuss their performance.