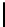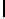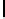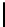Graphics Reference
In-Depth Information
// Compute contribution from third row.
41
load
=
vload16
(0,
in
+(
offset
+
width
2+0));
42
43
44
lData
=
convert short8
(
load
.
s01234567
);
mData
=
convert short8
(
load
.
s12345678
);
45
rData
=
convert short8
(
load
.
s23456789
);
46
47
48
_dx1
+=
rData
−
lData
;
_dy1
−
=
rData
+
lData
+
mData
(
short8
)2;
49
_dx2
+= (
rData
−
lData
)
(
short8
)2;
50
// Store the results .
62
vstore8
(
convert char8
(
_dx1
>>
3), 0,
dx1
+
offset
+
width
+1);
63
vstore8
(
convert char8
(
_dy1
>>
3), 0,
dy1
+
offset
+
width
+1);
64
vstore8
(
convert char8
(
_dx2
>>
3), 0,
dx2
+
offset
+
width
2+1);
65
vstore8
(
convert char8
(
_dy2
>>
3), 0,
dy2
+
offset
+
width
2+1);
66
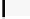
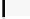
Listing 7.7.
Computing contribution from the third row:
2xchar8_load16
.
Computing two rows of output.
The
2xchar8
and
2xchar8_load16
kernels load from
four input rows to compute results for two output rows (
n
=2). Theyare
partially shown in Listing 7.6 and Listing 7.7 and are modifications of the
char8
and
char8_load16
kernels, respectively. Both kernels can be launched with up to
128 simultaneous work-items per core and both kernels perform better than the
single-row variants. As before, the
load16
version is faster, and indeed achieves
the second best performance in this study.
Computing three rows of output.
The
3xchar8
kernel, partially shown in List-
ing 7.8, has grown too complex and can only be launched with up to 64 simul-
taneous work-items per core. Therefore, exploiting data reuse by keeping more
than two rows in registers is suboptimal on the Mali-T604.
7.4.8 Summary
We have presented several versions of the Sobel filter, and discussed their per-
formance characteristics on the Mali-T604 GPU. Vectorizing kernel code and
exploiting data reuse are the two principal optimization techniques explored in
this study. The fastest kernel,
char16_swizzle
, is nearly nine times faster than
the slowest kernel,
char
, which reiterates the importance of target-specific opti-
mizations for OpenCL code.
To summarize, we note that although the theoretical peak performance is
at the ratio of two arithmetic instruction words for every load-store instruction
word, the best performance was obtained in the versions with the highest number
of arithmetic words executed per cycle. Restructuring the program to trade load-
store operations for arithmetic operations has thus been successful, as long as the
kernel could still be launched with 128 simultaneous work-items per core.