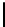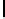Graphics Reference
In-Depth Information
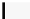
// Compute contribution from third row.
41
lLoad
=
vload16
(0,
in
+(
offset
+
width
2+0));
42
mLoad
=
vload16
(0,
in
+(
offset
+
width
2+1));
43
rLoad
=
vload16
(0,
in
+(
offset
+
width
2+2));
44
45
46
lData
=
convert short16
(
lLoad
);
mData
=
convert short16
(
mLoad
);
47
rData
=
convert short16
(
rLoad
);
48
49
50
_dx
+=
rData
−
lData
;
_dy
−
=
rData
+
lData
+
mData
(
short16
)2;
51
52
53
// Store the results .
vstore16
(
convert char16
(
_dx
>>
3) , 0,
dx
+
offset
+
width
+1);
54
vstore16
(
convert char16
(
_dy
>>
3) , 0,
dy
+
offset
+
width
+1);
55
Listing 7.3.
Computing contribution from the third row:
char16
.
7.4.6 Reusing Loaded Data
Larger load operations.
The
char8
kernel performed eight
char8
load operations.
The
char8_load16
kernel, partially shown in Listing 7.4, performs only three
char16
load operations: the required subcomponents are extracted by swizzle
operations, which are often free on the Midgard architecture. Table 7.1 confirms
that the number of memory operations per pixel is decreased, while still allowing
the kernel to be launched with up to 128 simultaneous work-items per core.
Eliminating redundant loads.
The
char16
kernel performed three
char16
load op-
erations to read 18 bytes for the first and third rows. The
char16_swizzle
ker-
nel, partially shown in Listing 7.5, performs two
char16
load operations for the
leftmost and rightmost vectors and reconstructs the middle vector by swizzle
operations.
// Compute contribution from third row.
41
load
=
vload16
(0,
in
+(
offset
+
width
2+0));
42
43
44
lData
=
convert short8
(
load
.
s01234567
);
mData
=
convert short8
(
load
.
s12345678
);
45
rData
=
convert short8
(
load
.
s23456789
);
46
47
48
_dx
+=
rData
−
lData
;
_dy
−
=
rData
+
lData
+
mData
(
short8
)2;
49
50
51
// Store the results .
vstore8
(
convert char8
(
_dx
>>
3) , 0,
dx
+
offset
+
width
+1);
52
vstore8
(
convert char8
(
_dy
>>
3) , 0,
dy
+
offset
+
width
+1);
53
Listing 7.4.
Computing contribution from the third row:
char8_load16
.