Graphics Reference
In-Depth Information
0
1
2
3
6
9
12
4
5
7810
11
13
14
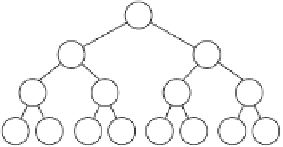
Figure 13.5
The van Emde Boas layout for a complete binary tree of height four. Numbers
designate node position in a linearized array representation.
The idea behind cache-oblivious algorithms and data structures is to optimize for
an ideal cache model with a cache line size
L
and a memory size
Z
, where both
L
and
Z
are unknown. Because
L
and
Z
can take on any value, the algorithm or data
structure is optimized for all cache levels within the memory hierarchy and therefore
also for widely differing CPU setups.
Several cache-oblivious algorithms, for example, the funnelsort algorithm, are
presented in [Prokop99]. Prokop also outlines how a binary tree can be output in a
cache-oblivious way, also referred to as the
van Emde Boas layout
[StøltingBrodal01].
Relevant not only to collision detection structures but to games in general, this inter-
esting tree layout is recursively defined. Given a tree
T
of height
h
, the tree is split
halfway across its height so
T
0
represents the tree of all nodes in
T
with height less
than
.
T
1
through
T
k
represent the subtrees of
T
rooted in the leaf nodes of
T
0
,
ordered left to right. The van Emde Boas representation of
T
is then the van Emde
Boas layout of
T
0
followed by the van Emde Boas layouts of
T
1
through
T
k
. Figure 13.5
illustrates the procedure for a binary tree of height four.
Although cache-aware methods are likely to perform better than cache-oblivious
ones in practice, cache-oblivious algorithms and data structures are especially inter-
esting in situations in which code is expected to run well on several different
platforms.
h
/2
13.5
Software Caching
For further improvements to the utilization of the low-level CPU data cache, it is use-
ful to implement custom software caches in applications. In this context, an especially
important concept is the idea of relying on caching for
data linearization
. Here, lin-
earization means the rearrangement of concurrently accessed but dispersed data into
contiguous blocks to improve performance by increasing spatial locality. By perform-
ing on-demand linearization and caching the result, it is possible to bring together
data at runtime that cannot practically be stored together otherwise. An example
would be the cached linearization of all leaves of a tree structure overlapped by a
coarse query volume to speed up subsequent queries within the initial volume.