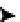Hardware Reference
In-Depth Information
Processor Pipeline
The ARM11 core has increased the length of its pipeline depth from three stages to eight stages. Each stage has a set
function and to a certain level having more stages allows you to process more data in the same clock cycle. This is
where some of the efficiency of each clock cycle comes in. So, is the pipeline like a water slide?
Well, no, but they do share one common theme though: each segment connects to the next. In the case of the
pipeline in the ARM, one stage's output is the next stage's input. Let's look at the ARM11's Algorithmic Logic Unit
(ALU) stage in Figure
1-3
. The ALU stage is responsible for all algorithmic functions, such as addition
or multiplication.
Order of execution
Stage 1
Stage 2
Stage 3
Stage 4
Stage 5
Stage 6
Stage 7
Stage 8
1st fetch
stage
2nd fetch
stage
Instruction
decode
Register read
and instruction
issue
Shift
stage
Main
ALU
Saturation
stage
Write back
stage
Figure 1-3.
Flow chart of instruction execution
The stages are executed in order from one to eight in one single clock cycle; so one clock cycle can provide one
ALU operation. Now think about if the pipeline was four stages long and not eight: it would then take two full clock
cycles to complete the same instruction. This makes the process half as efficient. However, the ARM11 is a superscalar
architecture so it can do more than one operation per clock cycle, as can most modern processors. Superscalar means
that functions inside the CPU core can operate in a parallel fashion. You can think of a superscalar architecture like a
grocery store with multiple checkout lines. You have many operators serving many customers. The opposite to this is
scalar: scalar would be a small green grocer with only one checkout that can serve only one person at a time.
Eight stages up from six must be better, right? To a certain degree it is: you now can get more done per clock cycle.
So why can't the ARM add 30 stages then? Very simple: the more stages you add, the higher the clock frequency
you need to drive the stage. This has the very unfortunate side effect of increased heat and power usage. Given that
the ARM11 is targeted to low power and low heat-embedded devices more stages would be very bad.
The ARMv6 is special in another way too; it is the first ARM core to contain a vector floating point coprocessor.
This coprocessor meets the IEEE standards for floating point arithmetic by giving the ARM11 a low-cost,
high-performance, single-precision and double-precision computation ability in hardware. A lot of the performance
improvements will come from this coprocessor that is potentially more than 10 times faster for certain operations.
■
A coprocessor is very much like a copilot. Its job is to assist the main process with functions that can be better
handled by the coprocessor, leaving the main processes free to handle the bigger tasks.
Note
To best illustrate how this will give increased performance I created some diagrams. First, in Table
1-4
we have
two ranges from 1 to 5: the first range will be called “A” and the second range will be called “B”.