Information Technology Reference
In-Depth Information
1995). The model presented here is comparatively sim-
ple, and has not been analyzed as extensively as some
of the other models in the literature. Nevertheless, the
current model may be unique in the number of known
properties of V1 representations that it captures based
on processing natural images. Although the Olshausen
and Field (1996) model used natural images, it did not
capture the topographic aspects of V1 representations.
Most other models use artificial input stimuli that may
not provide an accurate rendition of the statistics of nat-
ural images.
In the next section, we will see how these V1 rep-
resentations can provide the building blocks for more
elaborate representations in subsequent areas of the vi-
sual system.
Human
Arm
Forearm
Hand
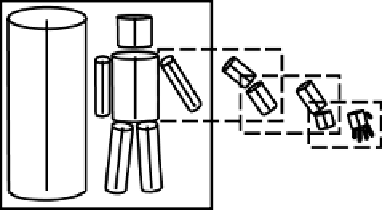
Figure 8.9:
Schematic of Marr's view of object recognition
based on a creating an internal 3-D model of the object, here
using a hierarchical system of cylinders.
the visual properties of the object's surfaces (figure 8.9).
Object recognition then amounts to matching the model
constructed from the perceptual input to the closest fit-
ting 3-D structure associated with known objects. The
advantage of this approach is that the 3-D structural rep-
resentation is completely invariant with respect to par-
ticular 2-D views, so that one only needs to store a sin-
gle canonical representation of an object, and it can then
be recognized from any viewpoint.
Hinton (1981) proposed a neural-network approach
to invariant object recognition that bears some re-
semblance to the Marr approach (see also Zemel,
Mozer, & Hinton, 1989). In Hinton's model, a com-
bined constraint-satisfaction search is performed simul-
taneously at two levels: (1) the parameters of a set of
transformation functions that operate on the input im-
age (e.g., rotation, translation, dilation, etc.), which are
used to transform the image into a canonical form; (2)
the match between the transformed image and a stored
canonical view. Again, the objective is to dynamically
construct a canonicalized representation that can be eas-
ily matched with stored, canonical object representa-
tions.
Both Marr's approach of producing a full 3-D struc-
tural model based on a given 2-D view, and Hinton's
approach of finding an appropriate set of canonical-
izing transformations, are exceedingly difficult search
problems. Essentially, there are many 2-D projections
that map onto many 3-D structures (or many trans-
formations that map onto many canonical representa-
8.4
Object Recognition and the Visual Form
Pathway
The next model simulates the object recognition path-
way that processes the visual form of objects (i.e., the
ventral “what” pathway). This model uses V1-like edge
detector representations at the lowest level and builds all
the way up to
spatially invariant
representations that
enable recognition of objects regardless of where they
appear in the visual input space, and over a range of dif-
ferent sizes. Because we focus on shape over other vi-
sual properties of objects (e.g., color, motion), it might
be more appropriate to consider the model one of
shape
recognition
, but the same basic principles should gener-
alize to these other object properties.
We take the development of spatially invariant repre-
sentations to be the defining characteristic of process-
ing in the ventral pathway: transformations collapse
across different spatial locations and sizes while pre-
serving distinctions among different objects. Although
only two forms of invariance (location and size) are sim-
ulated here, the same mechanisms should lead to at least
some degree of rotation invariance as well (note that
it appears that the brain does not exhibit a very high
degree of rotational invariance in its representations;
Tanaka, 1996).
The traditional approach to spatially invariant object
recognition (e.g., Marr, 1982) involves creating an in-
ternal 3-D model of the structure of the object based on

Search WWH ::

Custom Search