Information Technology Reference
In-Depth Information
Intuitively, this thought experiment makes clear that
the TD error signal provides a useful means of training
both the AC system itself, and also the actor. This dual
use of the TD signal is reflected in the biology by the
fact that the dopamine signal (which putatively repre-
sents the TD error
Æ(t)
) projects to both the areas that
control the dopamine signal itself, and the other areas
that can be considered the actor network (figure 6.16).
It should also be noted that many different varieties of
TD learning exist (and even more so within the broader
category of reinforcement learning algorithms), and that
extensive mathematical analysis has been performed
showing that the algorithm will converge to the correct
result (e.g., Dayan, 1992). One particularly important
variation has to do with the use of something called an
eligibility trace
, which is basically a time-averaged ac-
tivation value that is used for learning instead of the
instantaneous activation value. The role of this trace
is analogous to the
hysteresis
parameter
fm
prv
in the
SRN context units (where
fm
hid
is then
1
fm
prv
).
The value of the trace parameter is usually represented
with the symbol
, and the form of TD using this pa-
rameter as
TD
(
)
. The case we have (implicitly) been
considering is
TD
(0)
, because we have not included
any trace activations.
1
1
Stimulus
r
V(t)
^
V(t)
^
V(t)
γ
γ
V(t+1)
V(t+1)
V(1)
V(2)
V(2)
V(3)
V(3)
AC
r(3)
δ
δ
1
1
2
2
3
3
1
2
3
Time
Figure 6.21:
Computation of TD using minus-plus phase
framework. The minus phase value of the AC unit for each
time step is clamped to be the prior estimate of future rewards,
, and the plus phase is either a computed estimate of dis-
counted future rewards
V
(
t
+1)
, or an actual injected reward
^
V
(
t
)
(but not both — requiring an absorbing reward assump-
tion as described in the text).
r
(
t
)
First, let's consider what happens when the network
experiences a reward. In this case, the plus phase acti-
vation should be equal to the reward value, plus any ad-
ditional discounted expected reward beyond this current
reward (recall that the plus phase value is
V
(
t
+1)+
). It would be much simpler if we could consider
this additional
V
(
t
+1)
term to be zero, because then
we could just clamp the unit with the reward value in the
plus phase. In fact, in many applications of reinforce-
ment learning, the entire network is reset after reward
is achieved, and a new trial is begun, which is often re-
ferred to as an
absorbing reward
. We use this absorbing
reward assumption, and just clamp the reward value in
the plus phase when an external reward is delivered.
In the absence of an external reward, the plus phase
should represent the estimated discounted future re-
wards,
V (t +1)
. This estimate is computed by the
AC unit in the plus phase by standard activation updat-
ing as a function of the weights. Thus, in the absence
of external reward, the plus phase for the AC unit is ac-
tually an unclamped settling phase (represented by the
forward-going arrow in figure 6.21), which is in contrast
with the usual error-driven phase schema, but consistent
with the needs of the TD algorithm. Essentially, the ul-
timate plus phase comes later in time when the AC unit
r
(
t
)
6.7.2
Phase-Based Temporal Differences
Just as we were able to use phase-based activation dif-
ferences to implement error-driven learning, it is rela-
tively straightforward to do this with TD learning, mak-
ing it completely transparent to introduce TD learning
within the overall Leabra framework. As figure 6.19
makes clear, there are two values whose difference con-
stitutes the TD error
Æ
,
V (t)
and
V (t+1)+r(t)
. Thus,
we can implement TD by setting the minus phase acti-
vation of the AC unit to
, and the plus phase to
(figure 6.21). Thus, to the extent that
there is a network of units supporting the ultimate com-
putation of the AC
Æ
value, these weights will be auto-
matically updated to reduce the TD error just by doing
the standard GeneRec learning on these two phases of
activation. In this section, we address some of the issues
the phase-based implementation raises.
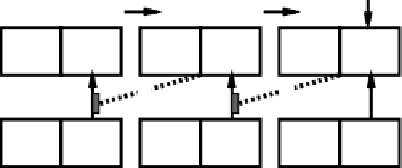

Search WWH ::

Custom Search