Information Technology Reference
In-Depth Information
Hidden
S
1
3
X
S
T
B
E
X
start
end
0
P
5
P
V
Targets
2
V
4
TSXVPE
TSXVPE
Output
T
Figure 6.13:
The simple finite-state grammar used by Reber
(1967). A string from the grammar is produced by starting
at the
start
, and generating the letter along the link followed,
with links chosen at each node at random with probability .5
for each. The string ends when
end
is reached. An example
string would be BTSSSXXTTVVE.
BTSXVP
Input
Context
Figure 6.14:
The FSA network, with input/output units rep-
resenting the surface letters, and an SRN-style context layer.
choices, the best a network can do is either activate both
of these choices, or pick one of the two at random. The
backpropagation network used by Cleeremans et al.
(1989) cannot pick items at random - it always pro-
duces a
blend
of the possible outputs. However, as we
will see in more detail in chapter 9, a Leabra network
can pick one of multiple possible output patterns essen-
tially at random, and we will take advantage of this in
this simulation.
The grammar that Reber (1967) used is shown in
figure 6.13. This figure describes a
finite state automa-
ton
(FSA) or
finite state grammar
, which generates a
string of letters by emitting the letter corresponding to
the link that the automaton takes as it jumps from node
to node. Thus, a sequence would be produced as fol-
lows: The automaton always starts in the
start
node (0),
which generates the letter
B
. Then, with equal (.5) prob-
ability, the next node is chosen (either 1 or 2), which
generates either the letter
T
or
P
. This process of proba-
bilistically going from node to node and generating the
letter along the link continues until the
end
node (and
the corresponding letter
E
) have been reached. Thus,
the connectivity of the nodes defines the regularities
present in the grammar.
Cleeremans et al. (1989) used an SRN to learn the
Reber grammar by training the network to predict the
next letter in the sequence (as the output of the network)
given the prior one as an input. If each link in the FSA
had a unique letter, this prediction task would be rel-
atively easy, because the input would uniquely identify
the location within the FSA. However, because different
links have the same letter, some kind of internal context
is necessary to keep track, based on prior history, of
where we are within the grammar. This keeping track is
what the context layer of the SRN does.
Because the next letter in the FSA sequence is ac-
tually chosen at random from among two possible
Open project
fsa.proj.gz
in
chapter_6
to begin
the exploration of FSA learning.
We begin by exploring the network (figure 6.14).
,
!
Click on
r.wt
and observe the connectivity.
Note in particular that the context layer units have a
single receiving weight from the hidden units. The con-
text units use this connection to determine which hid-
den unit to update from (but the weight is not used,
and just has a random value). Otherwise, the network
is standardly fully connected. Notice also that there is
a seemingly extraneous
Targets
layer, which is not
connected to anything. This is simply for display pur-
poses — it shows the two possible valid outputs, which
can be compared to the actual output.
Let's view the activations, and see a few trials of
learning.
,
!
Click on
act
in the network, and make sure the
Display
toggle is on. Then, press
Step
in the control
panel.
,
!
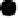













Search WWH ::

Custom Search