Information Technology Reference
In-Depth Information
petition encourages only one expert network to be active
at a time, which limits the extent that different experts
can cooperate to solve problems. Thus, the mixtures
of experts algorithm just makes the individual “units”
more powerful, but has the same limited overall dynam-
ics as other WTA systems. In contrast, one can think of
the effect of using a kWTA algorithm in a task-learning
context as a better kind of fine-grained mixtures of ex-
perts mechanism, in that it encourages the specializa-
tion of different units to different aspects of the task but
also allows cooperation and powerful distributed repre-
sentations.
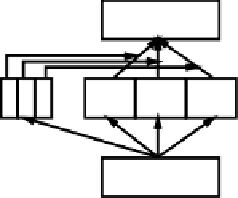
Output
Experts
Gating
Units
Input
Figure 6.2:
The mixtures-of-experts architecture, where the
gating units undergo a soft WTA competition (aka softmax),
and their output gates (multiplies) the contribution of their
corresponding expert to the problem.
6.2.4
Implementation of Combined Model and Task
Learning
imposes a bias toward forming sparse distributed repre-
sentations (models) of the environment, and is an essen-
tial aspect of the Hebbian model-learning framework, as
we saw in the self-organizing exploration in chapter 4.
Although inhibitory competition of one form or an-
other has long been used in a model learning context, it
has not been used much in a task learning context. This
is in part because a form of competition that allows dis-
tributed representations to develop (e.g., kWTA), which
is essential for solving most interesting tasks, has not
been widely used. The error derivatives of a compet-
itive activation function, especially one that allows for
distributed representations, can be also difficult to com-
pute. As we saw in chapter 5, these derivatives are
important for error-driven learning. We can avoid the
derivative problem by using the GeneRec algorithm, be-
cause it computes the derivatives implicitly.
One context where something like inhibitory com-
petition has been used in a task learning situation is
in the
mixtures of experts
framework (Jacobs, Jor-
dan, Nowlan, & Hinton, 1991), illustrated in figure 6.2.
Here, a “soft” WTA (winner-take-all) competition takes
place among a special group of units called the
gating
units, which then provide a multiplicative modulation of
the outputs of corresponding groups of other units (the
experts
), which can specialize on solving different parts
of the overall task.
Although each expert group can have distributed rep-
resentations, many of the same limitations of WTA al-
gorithms that operate on individual units apply here as
well. For example, the extreme nature of the WTA com-
The implementation of combined model and task learn-
ing is quite straightforward. It amounts to simply
adding together the weight changes computed by Heb-
bian model learning with those computed by error-
driven task learning. There is an additional parameter
hebb
(
hebb
in the simulator, which is a component
of the
lmix
field that has
err
that is automatically
set to
1-hebb
) that controls the relative proportion or
weighting of these two types of learning, according to
the following function:
(6.1)
where the two learning components
hebb
and
err
are
given by the CPCA Hebbian rule (equation 4.12) and
the CHL GeneRec error-driven rule (equation 5.39), re-
spectively.
The
hebb
parameter is typically .01 or smaller (rang-
ing down to .0005), and values larger than .05 are rarely
used. This small magnitude reflects our emphasis on
error-driven learning, and also some inherent differ-
ences in the magnitudes of the two different learning
components. For example, error signals are typically
much smaller in magnitude (especially after a bit of
training) than Hebbian weight changes. Hebbian learn-
ing is also constantly imposing the same kind of pres-
sure throughout learning, whereas error signals change
often depending on what the network is getting right
and wrong. Thus, the relative consistency of Hebbian
learning makes it have a larger effective impact as well.
Search WWH ::

Custom Search