Cryptography Reference
In-Depth Information
How exactly do we exploit these language characteristics? This isn't terribly difficult, even without a com-
puter. The trick is to write out two or more copies of the ciphertext
vertically,
so that each ciphertext strip looks
like
We take out the two or more copies of this sheet we have made, and line them up side by side. We then use
the
sliding window technique
— essentially moving the sheets of paper up and down with respect to each oth-
er. Then we measure how common the digraphs (and trigraphs with three letters, or 4-graphs with four letters,
etc.) found in the resulting readout are. Next, we measure how far apart they are (in characters), and this length
will be the number of
rows
(represented as
r)
in the matrix used to write the ciphertext. We then calculate the
number of columns (based on dividing the ciphertext size by the number of rows and rounding up), so that we
have the original key
(k,
the number of columns).
To show this method, let's take the first transposition-cipher example ciphertext (from Section 1.4.1) and
showhowtobreakitusingtheslidingwindowtechnique.Theciphertextobtainedfromencrypting
"all work
and no play..."
was
AKPKNL LALENL LNASYB WDYJAO ONMODY ROAHU
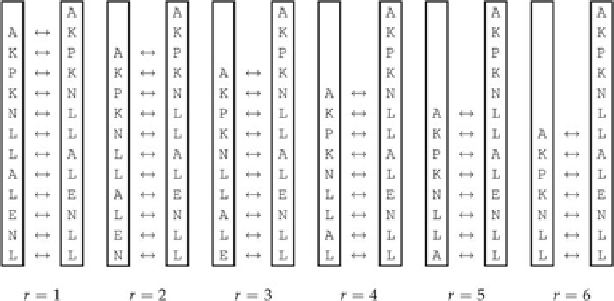
The sliding windows for this ciphertext are shown in
Figure 1-3
.
Figure 1-3
Sliding window technique example for
r
= 1, ... , 6.
Examining the example in
Figure 1-3
can reveal a great deal about the best choices. Looking at
r
= 1, we
have letter pairs in the very beginning such as
KP
and
PK.
We can consult a table of digraphs and trigraphs
to check to see how common certain pairs are, and note that these two letter pairs are very infrequent. For
r
= 2, letter pairs such as
KK
and
PN
are also fairly uncommon. It would not be too difficult to create a simple
measurement of, say, adding up the digraph probabilities with all of the pairs in these examples, and comparing
them.
However, a word of caution is necessary — since we removed all of the spaces, there is no difference
between letter pairs
inside
a word and letter pairs
between
words. Hence, the probabilities will not be perfect
representations, and we cannot simply always go for the window with the highest probability sum.

Search WWH ::

Custom Search