Cryptography Reference
In-Depth Information
First, as shown above, if the input to the round function (
f
) is the same (with a zero XOR), then the output
is the same. The new left half in both cases is the old right half (which is the same, since there is a zero XOR).
The new right half is the XOR of the round function value (which is the same) and the old left half, which has a
differential of Ω
L
. The characteristic can be written as
Furthermore, there is no guessing in this; thus, this characteristic has a probability of 1.
Let's construct another good characteristic. Again, assuming a constant differential for the left half (Ω
L
), if
we consider the right half having the differential
60 00 00 00
, then the input to the round function will also
have that same XOR. Using S-box analysis, we can show that the output differential of the round function
00
80 82 00
occurs with probability 14/64. This differential would then be XORed with the previous differential
(Ω
L
), to obtain the following one-round characteristic:
Now that we have these two characteristics, we can combine them to create a fairly good three-round char-
acteristic. To see how this is done, simply look at the previous characteristic, and assume that Ω
L
=
00 80 82
00
.
In this case, we will have the following chain, using the second, first, and second characteristics in that order:
This is an example of an iterative characteristic: It yields itself after several rounds. Therefore, these can be
chained together to create larger and larger characteristics.
Cryptanalysis of DES itself using this characteristic, as well as a few others, gives us an approximation for
enough of the cipher to start brute-forcing particular subkey bits.
7.8 Analysis
Now that we have seen exactly how to perform differential cryptanalysis, it's fair that we should attempt to ana-
lyze its operations and discuss some of its properties.
As we have shown, differential cryptanalysis has two primary features: It is a probabilistic attack, and it is a
chosen-plaintext attack. Neither of these scenarios is ideal, but we are stuck with them.
The implications of this probabilistic attack are similar to the properties of other probabilistic problems. We
aren't guaranteed to get good results, even with perfectly good inputs and a sufficient number of chosen plain-
texts. The more chosen plaintexts we do have, however, the more likely we are to succeed.
Another disadvantage of this method is that we will come up with an answer no matter what; the answer will
just be incorrect if we don't have a sufficient number of texts to test it against. Furthermore, there is no way to
tell if the key bits derived are correct until we derive all the rest of the key bits and actually test encrypting the
plaintext with the potential key (unless we know the answer ahead of time).
The fact that this algorithm is chosen plaintext is another step back: Chosen plaintexts represent some of the
most stringent conditions of a cryptanalytic attack. They require the cryptanalyst to not only know and under-
stand the cryptographic algorithm being used, have developed a plan of action against it, and collected a large

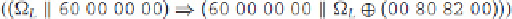

Search WWH ::

Custom Search