Robotics Reference
In-Depth Information
the meaning of phrases and sentences takes on a particular slant pre-
cisely
because
the wording comes from an ad. Then consider the third
possibility—there is no reason to believe that the computer knows any-
thing about your mother or will ever know anything about your mother,
so how could it understand your mother? Version 3 therefore appears
most unlikely to be the intended meaning of the sentence. So here we
have one positive reason why a human would most likely understand the
meaning to be the first version, and one negative reason why a human
would be unlikely to plump in favour of the third version. This type
of linguistic thinking is trivial, almost sub-conscious for humans, but
extremely problematical for computer programs.
The traditional approaches to NLP involve a number of different
process of understanding natural language starts with the input text
which, in an ideal world, is made up of grammatically correct sentences.
The first stage, which is called syntactic analysis, determines the gram-
matical structure of each sentence. (Of course, spoken and written lan-
guage sometimes include grammatically incorrect sentences, mis-spelled
words and lone phrases rather than sentences, all of which point to addi-
tional difficulties faced by NLP systems.) Syntactic analysis investigates
how the words in a sentence are grouped into noun phrases, verb phrases
and the other constituent parts of the sentence, and requires the software
to be able to assign parts of speech (noun, verb, adjective, adverb, etc.)
to each word. Determining parts of speech is itself far from easy, partly
because some words can be used as more than one part of speech. For
LEXICON
SYNTACTIC
PARSER
Grammatical
Structure
SEMANTIC
ANALYSER
TEXT
Meaning
SEMANTIC
DICTIONARY
GRAMMAR
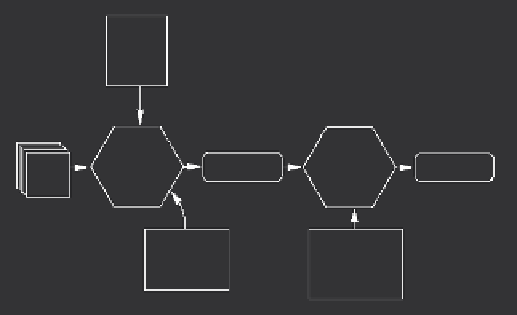
Figure 50.
The modules of a traditional Natural Language Processing system