Database Reference
In-Depth Information
An introduction to Spark Streaming
There are a few different general techniques to deal with stream processing. Two of the
most common ones are as follows:
• Treat each record individually and process it as soon as it is seen.
• Combine multiple records into
mini-batches
. These mini-batches can be delin-
eated either by time or by the number of records in a batch.
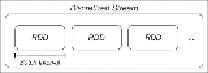
Spark Streaming takes the second approach. The core primitive in Spark Streaming is the
discretized stream
, or
DStream
. A DStream is a sequence of mini-batches, where each
mini-batch is represented as a Spark RDD:
The discretized stream abstraction
A DStream is defined by its input source and a time window called the
batch interval
. The
stream is broken up into time periods equal to the batch interval (beginning from the start-
ing time of the application). Each RDD in the stream will contain the records that are re-
ceived by the Spark Streaming application during a given batch interval. If no data is
present in a given interval, the RDD will simply be empty.
Input sources
Spark Streaming
receivers
are responsible for receiving data from an
input source
and
converting the raw data into a DStream made up of Spark RDDs.
Spark Streaming supports various input sources, including file-based sources (where the re-
ceiver watches for new files arriving at the input location and creates the DStream from the
contents read from each new file) and network-based sources (such as receivers that com-
municate with socket-based sources, the Twitter API stream, Akka actors, or message
queues and distributed stream and log transfer frameworks, such Flume, Kafka, and
Amazon Kinesis).