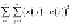Database Reference
In-Depth Information
K-means clustering
K-means attempts to partition a set of data points into K distinct clusters (where K is an in-
put parameter for the model).
More formally, K-means tries to find clusters so as to minimize the sum of squared errors
(or distances) within each cluster. This objective function is known as the
within cluster
sum of squared errors
(
WCSS
).
It is the sum, over each cluster, of the squared errors between each point and the cluster
center.
Starting with a set of K initial cluster centers (which are computed as the mean vector for
all data points in the cluster), the standard method for K-means iterates between two steps:
1. Assign each data point to the cluster that minimizes the WCSS. The sum of
squares is equivalent to the squared Euclidean distance; therefore, this equates to
assigning each point to the
closest
cluster center as measured by the Euclidean dis-
tance metric.
2. Compute the new cluster centers based on the cluster assignments from the first
step.
The algorithm proceeds until either a maximum number of iterations has been reached or
convergence
has been achieved. Convergence means that the cluster assignments no longer
change during the first step; therefore, the value of the WCSS objective function does not
change either.
Tip
For more details, refer to Spark's documentation on clustering at
http://spark.apache.org/