Database Reference
In-Depth Information
Training and using regression models
Training for regression models using decision trees and linear models follows the same
procedure as for classification models. We simply pass the training data contained in a
[LabeledPoint]
RDD to the relevant
train
method. Note that in Scala, if we wanted
to customize the various model parameters (such as regularization and step size for the
SGD optimizer), we are required to instantiate a new model instance and use the
optim-
izer
field to access these available parameter setters.
In Python, we are provided with a convenience method that gives us access to all the avail-
able model arguments, so we only have to use this one entry point for training. We can see
the details of these convenience functions by importing the relevant modules and then call-
ing the
help
function on the
train
methods:
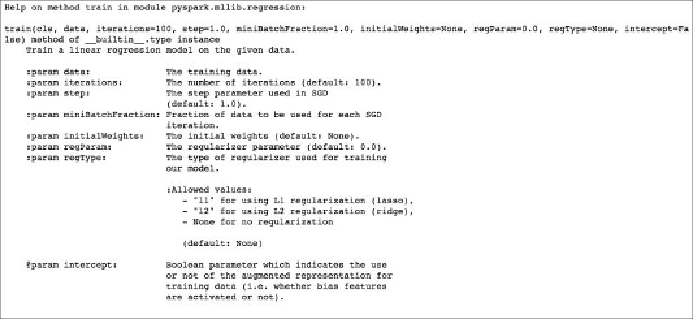
from pyspark.mllib.regression import LinearRegressionWithSGD
from pyspark.mllib.tree import DecisionTree
help(LinearRegressionWithSGD.train)
Doing this for the linear model outputs the following documentation:
Linear regression help documentation