Geography Reference
In-Depth Information
Separation may be easier in higher dimensions
Feature (n+1)
A+
Feature map
γ
γ
Support Vectors
Support Vectors
A-
Separating hyperplane
Complex in low dimensions
Simple in higher dimensions
Hyperplan
Feature (n)
Input Space
Feature Space
Fig. 5.39 Geometric explanation for the linear classification of SVM (Source modified from
Vapnik
1998
)
SVM
The Support Vector Machine (SVM) classification algorithm is based on statistical
learning theory as proposed by Vapnik and Chervonenkis (
1971
). It is discussed in
detail by Vapnik (1995) and Schölkopf and Smola (
2002
). The SVM is a newly
developed method to train polynomial, radial basis function, or multilayer per-
ceptron classifiers. Bennet and Campbell (
2000
) gave a geometric clarification of
how the support vector machines functioned (Fig.
5.39
). An overview on the
application in remote sensing is given by Gualtieri and Cromp (
1998
), Huang et al.
(
2002
), Melgani and Bruzzone (
2004
), Pal and Mather (
2005
,
2006
), and Wat-
anachaturaporn et al. (
2006
).
SVMs were at first presented as a binary classifier (Vapnik
1998
). The idea is
based on fixing an Optimal Separating Hyper-plane (OSH) to the training samples
of two classes, so the pixels from each tested class are at last on the right side of
the hyper-plane. The optimization problem that has to be removed is based on the
minimization of structural risk. Its goal is to maximize the borders between the
OSH and the nearest neighboring training samples, the so-called support vectors
(Vapnik
1998
). So, the model just considers samples nearly from the class
boundary and operates well with small training samples, even when high dimen-
sional data sets are used in classification (Pal and Mather
2006
). Foody and Mathur
(
2004b
) indicated that a complete description of each class is not necessary for an
accurate classification. While only samples close to the hyper-plane are measured,
other training data has no influence on the interpretation. However, a larger
number of training samples guarantees the employment of sufficient samples
(Foody and Mathur
2004b
).
In contrast to other classification algorithms (e.g., decision tree), the initial
output of a SVM does not have the final class label. The outputs include the
distances of each pixel to the OSH-plane (rule images). These rule images can then
be utilized to verify the final class membership that is based on the multiclass
strategy. This principle is furthermore known as ''winner takes all'', where only
one value (the maximum) is used for choosing the membership. Contrary to these















































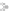













































Search WWH ::

Custom Search