Information Technology Reference
In-Depth Information
Job
configuration
Distributed file system
Master
Mapper
Reducer
Input data
Mapper
Output data
Reducer
Mapper
Data
splits
Intermediate
results
Final
results
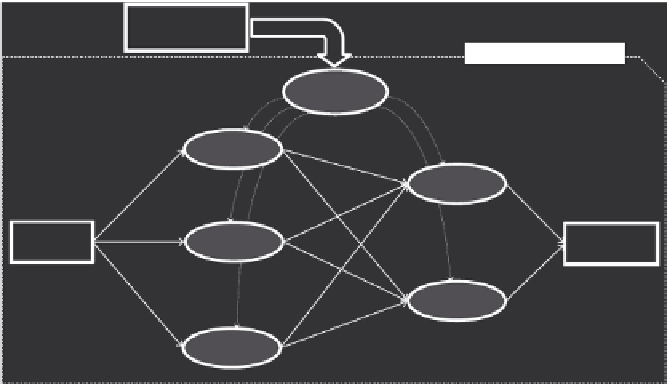
FIGURE 17.1
Execution phases in a generic MapReduce application.
For more complex data processing procedures, multiple MapReduce calls
may be linked together in sequence.
The MapReduce programs can be used to compute derived data from
documents such as inverted indexes, and the processing is automatically
parallelized by the system that executes on large clusters of commodity-
type machines, highly scalable to thousands of machines. Since the sys-
tem automatically takes care of details like partitioning the input data,
scheduling and executing tasks across a processing cluster, and manag-
ing the communications between nodes, programmers with no experience
in parallel programming can easily use a large distributed processing
environment.
17.2.1 Google File System (GFS)
Google File System (GFS) is the storage infrastructure that supports the
execution of distributed applications in Google's computing cloud. GFS was
designed to be a high-performance, scalable distributed file system for very
large data files and data-intensive applications providing fault tolerance and
running on clusters of commodity hardware. GFS is oriented to very large
files dividing and storing them in fixed-size chunks of 64 Mb by default,
which are managed by nodes in the cluster called chunkservers. Each GFS
consists of a single master node acting as a nameserver and multiple nodes in
the cluster acting as chunkservers using a commodity Linux-based machine
(node in a cluster) running a user-level server process. Chunks are stored in
plain Linux files, which are extended only as needed and replicated on mul-
tiple nodes to provide high availability and improve performance.
Search WWH ::

Custom Search