Information Technology Reference
In-Depth Information
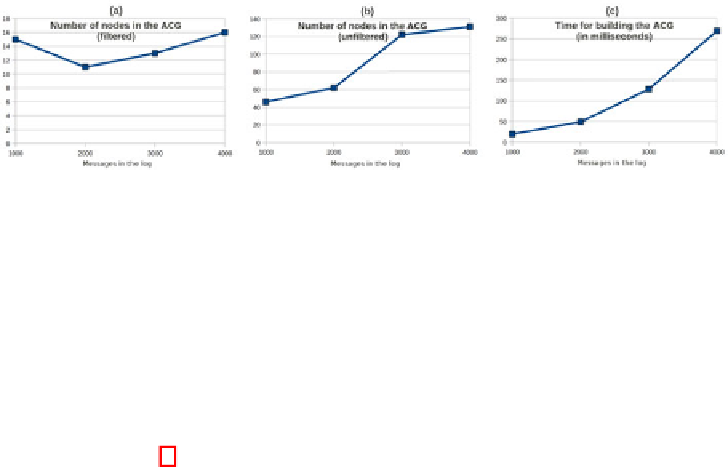
Fig. 4.
Impact of log size on filtered ACG size (a), on unfiltered ACG size (b), and on
processing time for generating the ACG (c)
become represented in the ACG. Thus, processing more messages would lead to
increasing the size of existing nodes and the weight of existing edges but not
increasing the number of nodes or edges. The stability in the number of nodes
of the ACG makes the proposed approach effective in generating a useful ACG
regardless of the size of the message interaction log.
The third and last analysis concerns the processing time needed to generate
the ACG. Figure 4 (c) shows the time needed to build the ACG from service
interaction logs of various sizes. Although the size of the ACG is stabilized over a
certain number of messages, it is required to process all available messages from
the log, just in case additional unexpected sequences of correlation conditions
may occur. Therefore, it takes longer to process a larger log as illustrated in
figure 4 (c).
5 Related Work
The need for automated approaches to message correlation in Web services has
first been reported in [4] where a real situation on how to correlate service
messages is presented. A categorization of various correlation methods in Web
service workflows are presented in [1]. However, no automated support for mes-
sage correlation is reported. The need for automated approaches for correlation
of service messages in composite business applications is also raised in IBM
Websphere platform [9]. This work presents an approach for the discovery of
correlation identifiers in messages from the log of service interactions. This ap-
proach identifies the correlation between message types (e.g., PurchaseOrder and
Invoice message types). This approach only considers atomic conditions, while
we also consider composite correlation conditions. Also, this approach only con-
cerns correlations between pairs of message types which does not allow to reason
at the process instance level.
In related work also Web usage mining investigates the problem of session
reconstruction [10]. A session represents all the activities of a user on a Web site
during a single visit. Identification of users is usually achieved using cookies and
IP addresses, if available, or through heuristics on the duration and behavior of
the user. By contrast, when correlating messages, we assume that the correlation