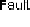Information Technology Reference
In-Depth Information
SS-S
i
τ
SSR
is a timer used by SS-R
j
to process Refresh() messages
received from its senders.
Bottom-up fault management involves three major tasks:
fault detection
,
fault
propagation
, and
fault reaction
. The sequence diagram in Fig. 4 depicts the relation-
ship between these tasks:
∈
Senders(SS-R
j
).
Fig. 4.
Sequence Diagram for Bottom-up Fault Management
•
Fault detection
: SS-S
i
first detects faults that occurred in the attached WS
i
. SS-S
i
does not need to detect physical and status change faults in WS
i
as these are im-
plicitly propagated to receivers if the latter do not receive Refresh() messages
from faulty senders. Participation refusal faults are communicated to SS-S
i
using
one of the techniques mentioned in Section 2.1. Policy changes in WS
i
may be
detected by SS-S
i
using various techniques. For instance, SS-S
i
may use XML
version control algorithms to detect changes in WS
i
policy specifications; another
solution is to provide an interface in SS-S
i
through which WS
i
provider submits
all policy changes; a third solution is to use the publish/subscribe model [3]
where SS-S
i
subscribes with WS
i
on policy changes. Due to space limitations,
details about the detection of participation refusals and policy changes are out of
the scope of this paper.
•
Fault propagation
: SS-S
i
then propagates the fault detected in the previous phase
to SS-R
j
. We propose a soft-state protocol for fault propagation. Details about
this protocol are given in Section 3.
•
Fault Reaction
: Finally, SS-Rj and/or CSj execute appropriate measures to react to
the fault. The techniques proposed in [12,7] can be extended for that purpose. In
[12], we use ECA (Event Condition Actions) to react to changes: the event part of
an ECA rule refers to change notifications; the action part allows for the specifica-
tion of change control policies; the use of conditions allows the specialization of