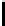Information Technology Reference
In-Depth Information
Table 2.
Precision in detecting
has-a
relationships
Del.icio.us CiteULike LibraryThing IMDb
Precision
51.6%
61.9%
55.5%
33.3%
7.3 Evaluation of ONTECTAS in Detecting
is-a
Relationships
Inthefollowing,wefocuson
is-a
relationships. All competing algorithms do not
distinguish between
is-a
and other relationships such as synonyms, whereas we
clearly isolate
is-a
relationships. We lump all other relationships into
any
and
compare the performance of ONTECTAS on
is-a
with that of other algorithms
on
, giving them an advantage, since in this evaluation, we do
not give credit to ONTECTAS for correctly finding
is-a
and
any
relationships. We use
the following standard performance measures: (1) Precision: We consider the
precision of ONTECTAS on
has-a
.
Precision for both is the number of correct edges over the number of all edges. (2)
Maximum depth and average depth of the
is-a
with that of other algorithms on
is-a
+
any
taxonomy. (3) Average number
of children. A higher value of the last two measures implies richer ontology is
extracted. In addition, following [19], we compare all algorithms with a gold
standard to see how they fare in trying to recreate manually-curated ontologies.
For depth and breadth metrics, we calculate these metrics on an ontology
with only correct relationships to ensure algorithms cannot earn an artificially
and unfairly high score on these by finding many incorrect relationships!
Absolute recall for ontology extraction from a large CTS is very hard to
measure. Instead, we propose a new metric:
relative recal l
. Relative recall for
an algorithm is the number of valid
is-a
is-a
relationships found by the algorithm
divided by the total number of valid
is-a
relationships found by all algorithms.
7.4 Comparing ONTECTAS to Other Algorithms
We compare ONTECTAS with the four algorithms from Section 2: 1) the algo-
rithm from [19] (abbreviated “LFZ”) 2) the DAG algorithm [5] (“DAG-ALG”) 3)
Schmitz's algorithm [23] (“Schmitz”), and 4) Barla and Bielikova's algorithm [3]
(“BB”). Since these algorithms cannot process the IMDb dataset due to the
lack of user information, we only compare them on Del.icio.us, LibraryThing,
and CiteULike.
To have a fair comparison, we implemented the above algorithms as closely
as possible to the way their authors had implemented them; we used the param-
eters that were described in the papers and contacted the authors for additional
information about how to make their algorithms as competitive as possible.
Validating the edges manually required that each algorithm output a small
number of edges. To do so, we put another threshold on the number of times a
tag, an item, or a user must occur in order to be considered. To be fair, we used
the same threshold to ensure that each algorithm output fewer than 150 edges.