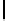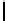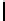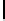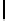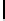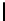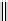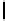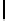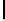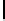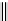Information Technology Reference
In-Depth Information
Ta b l e 6 .
Experiment results. Numbers of found/addressed deficiencies.
Generated Subject Manual Generated
confirmed
Manual
∩
Generated Manual
∩
Generated
confirmed
Automaton,
questions
referring to the
text
1
32
1
1
1
2
30
1
1
1
21
3
13
0
0
0
4
29
19
0
0
1
38
73
0
0
MSCs, questions
referring to the
model
2
38
46
5
5
87
3
25
43
0
0
4
16
52
0
0
1
9
1
0
0
Automaton,
questions
referring to the
model
2
4
5
0
0
21
3
11
0
0
0
4
14
2
0
0
5
12
1
0
0
1
26
31
8
8
MSCs, questions
referring to the
text
2
18
7
1
1
50
3
19
28
3
1
4
11
27
0
0
5
14
1
0
0
found that the generated questions do not address genuine problems of the specifica-
tion. Thus, the experiment hypothesis has to be rejected for the automaton-based speci-
fication. For the Instrument Cluster Specification (MSCs), however, the subjects found
that many more generated questions address genuine problems of the specification text.
The fraction of questions addressing genuine problems (column “Generated
confirmed
”
of Table 6) varies from 2% (1 out of 50) to 84% (73 out of 87). It looks like the number
of generated questions addressing genuine problems is higher for the questions refer-
ring to the model than for the questions referring to the text: For the questions referring
to the text, at most 31 out 50 questions (62%) are found to address genuine problems.
For the questions referring to the model, though, this rate varies from 49% (43 out of
87) to 84% (73 out of 87). The size of the sample, though, is too small to claim that
questions referring to the model better help to detect specification problems.
The most interesting finding of the experiment is presented in the last two columns of
Table 6: the manually found problems and the problems addressed by the automatically
generated questions are almost always disjoint. The figures in both columns coincide,
except for one line. This line results from the following situation: the subject marked
two sentences as problematic. The tool marked the same two sentences as problematic
too. However, the subject did not confirm the generated questions as addressing gen-
uine problems. The most probable reason is that the subject saw different problems in
these sentences than the tool. However, as the subject did not explicitly write down the
identified problems, this remains solely our interpretation of the discrepancy.
Two last columns of Table 6, together with the number of generated questions that
the subjects found to address genuine specification problems, allow us to claim that
the hypothesis is confirmed for the Instrument Cluster Specification, namely, that the
automatically generated questions address deficiencies of the specification that would
be overseen by human analysts.