Database Reference
In-Depth Information
Utilizing a sharding key
A sharded cluster uses a shard key to divide and partition the entire dataset into smaller
pieces. A shard key is an indexed key or indexed compound key that exists in all records in
the collection. After defining the shard key and the size of each chunk, the engine splits the
dataset into smaller chunks and syncs them with shards.
Mainly, a shard key can be either range-based or hash-based. Using range-based keys,
MongoDB divides the dataset into specific ranges. In hash-based keys, the engine creates
hashes from the given field and divides the dataset using those hashes. In the next chapter,
we will use both methods to create shard key using real-world examples.
In the next section, we will talk about each technique in detail.
Understanding range-based keys
One of the methods to define a key is to use a range-based mechanism. Using range-based
keys, the database engine splits the dataset into smaller parts with specific ranges of the
given field's value.
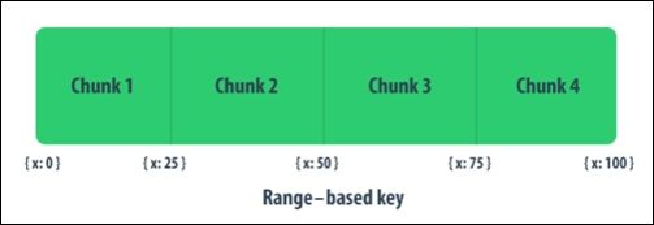
For instance, you have a field that has numeric value and value ranges between 0 and 100.
By introducing this field and configuring chunk sizes to four chunks, you will have four
shards and the first chunk's data starts from the minimum value of the introduced field; the
last chunk ends with the maximum value of the field.
The following diagram illustrates the usage of range-based keys in a sharded cluster: