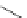Information Technology Reference
In-Depth Information
3
3
Sink
2
2
1
1
4
4
Fig. 1.
Sensor nodes connected to a base station by means of a multi-hop routing tree. Grayed
circles indicate overlapping communication regions.
as the relaying node for the multi-hop routing. An example of multi-hop shortest path
routing structure is given in Fig. 1, together with the radio communication ranges of
sensor nodes.
Since communication is the most energy expensive action, it is clear that in order
to save energy, a node should turn off its antenna (or go to sleep) [5]. However, when
sleeping, the node is not able to send or receive any messages, therefore it increases
the latency of the network, i.e., the time it takes for messages to reach the sink. High
latency is undesirable in any real-time applications. On the other hand, a node does not
need to listen to the channel when no messages are being sent, since it loses energy
in vain. As a result, nodes should determine on their own
when
they should be awake
within a frame. This behavior is called
wake-up scheduling
. Once a node wakes up, it
remains active for a predefined amount of time, called
duty cycle
.
Wake-up scheduling in wireless sensor networks is an active research do-
main [7,12,8,2]. A good survey on wake-up strategies in WSNs is presented in [14].
The standard approach is S-MAC, a synchronized medium access control (MAC) pro-
tocol for WSN [17]. In S-MAC, the duty-cycle is fixed by the user, and all sensor nodes
synchronize in such a way that their active periods take place at the same time. This syn-
chronized active period enables neighboring nodes to communicate with one another.
The use of routing then allows any pair of nodes to exchange messages. By tuning the
duty-cycle, wake-up scheduling therefore allows to adapt the use of sensor resources to
the application requirements in terms of latency, data rate and lifetime [14].
Recently, we showed that the wake-up scheduling problem could be efficiently tack-
led in the framework of multi-agent systems and reinforcement learning. In wireless
sensor networks, the sensor nodes can be seen as agents, which have to logically self-
organize in groups (or
coalitions
). The actions of agents within a group need to be
synchronized (e.g., for data forwarding), while
at the same time
being desynchronized
with the actions of agents in other groups (e.g., to avoid radio interferences). We refer
to this concept for short as
(de)synchronicity
.
Coordinating the actions of agents (i.e., sensor nodes) can successfully be done us-
ing the reinforcement learning framework by rewarding successful interactions (e.g.,
transmission of a message in a sensor network) and penalizing the ones with a negative
outcome (e.g., overhearing or packet collisions) [10]. This behavior drives the nodes