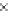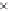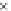Information Technology Reference
In-Depth Information
Ta b l e 1 .
Image similarity based classifier (
Φ
s
) performance obtained using various image simi-
larity functions
s
1
- Avg 1-NN
s
m
- Perc. of Matches
s
ı
- Avg Sim. Ratio
s
h
- Hough Transform
similarity function
version
Te Tr or and avg Te Tr or and avg Te Tr or and avg Te Tr or and avg
SIFT
.75 .52 .55 .85 .82 .88 .80 .81 .90 .88 .89 .80 .81 .91 .89 .92 .88 .88
.93
.91
SURF
.79 .70 .73 .80 .82 .85 .73 .76 .88 .86 .82 .73 .75 .87 .84 .89 .76 .79
.92
.86
SIFT
.72 .55 .56 .84 .84 .86 .80 .80 .89 .86 .87 .80 .81 .91 .88 .90 .87 .86
.93
.90
SURF
.76 .67 .70 .78 .80 .83 .70 .74 .87 .84 .81 .68 .73 .86 .82 .87 .74 .77
.89
.85
SIFT
.73 .52 .55 .85 .82 .88 .78 .80 .90 .88 .89 .78 .80 .91 .88 .91 .87 .87
.93
.91
SURF
.79 .63 .67 .80 .82 .81 .60 .62 .86 .79 .81 .63 .64 .84 .76 .87 .66 .68
.90
.81
SIFT
.72 .55 .53 .84 .84 .86 .78 .80 .89 .86 .87 .79 .80 .90 .87 .90 .86 .86
.92
.90
SURF
.76 .63 .67 .78 .80 .79 .65 .65 .84 .78 .80 .67 .67 .83 .77 .85 .68 .70
.89
.81
SIFT
91111174231553523921
SURF
36811082408371415918
SIFT
11111174331553528599
SURF
16311889308571414038
Acc
Best
F
1
Acc
k
=1
F
1
Acc
Best
k
F
1
ϭ͘Ϭ
ϭ͘Ϭ
Ϭ͘ϵ
Ϭ͘ϵ
Ϭ͘ϴ
Ϭ͘ϴ
Ϭ͘ϳ
Ϭ͘ϳ
Ϭ͘ϲ
Ϭ͘ϲ
Ϭ͘ϱ
Ϭ͘ϱ
Ϭ͘ϰ
Ϭ͘ϰ
Ϭ͘ϯ
^/&dĐĐƵƌĂĐLJ
^hZ&ĐĐƵƌĂĐLJ
^/&dDĂĐƌŽ&ϭ
^hZ&DĂĐƌŽ&ϭ
Ϭ͘ϯ
Ϭ͘Ϯ
Ϭ͘Ϯ
Ϭ͘ϭ
^/&d
^hZ&
Ϭ͘ϭ
Ϭ͘Ϭ
Ϭ͘Ϭ
Ϭ
Ϭ͘ϭ Ϭ͘Ϯ Ϭ͘ϯ Ϭ͘ϰ Ϭ͘ϱ Ϭ͘ϲ Ϭ͘ϳ Ϭ͘ϴ Ϭ͘ϵ
ϭ
Ϭ
ϭϬ
ϮϬ
ϯϬ
ϰϬ
ϱϬ
ϲϬ
ϳϬ
ϴϬ
ϵϬ ϭϬϬ
dŚƌĞƐŚŽůĚ
Đ
ƵƐĞĚĨŽƌůŽĐĂůĨĞĂƚƵƌĞƐŵĂƚĐŚŝŶŐ
Ŭ
Fig. 3.
Accuracy and Macro
F
1
for various
matching thresholds
c
, obtained by the image
similarity based classifier (
Φ
s
)usingthe
s
m,Tr
similarity and SIFT
Fig. 2.
Accuracy obtained by both SIFT and
SURF for various
k
using the
s
m,Te
similarity
function with the image similarity based clas-
sifier
This is more evident in Figure 2 where we report the
accuracy
obtained for
k
between
1 and 100 by both SIFT and SURF using the
s
m,Te
similarity function. SIFT obtains
the best performance for smaller values of
k
with respect to SURF. Moreover, SIFT
performance is generally higher than SURF. It is interesting to note that performance
obtained for
k
=1
is typically just slightly worst than that of the best
k
. Thus,
k
=1
gives very good performance even if a better
k
could be selected during a learning
phase.
Two of the similarity measures proposed in Section 4.3 require a parameter to be set.
In particular, the similarity measures
Percentage of Matches
(
s
m
)and
Hough Transform
Matches Percentage
(
s
h
) use the matching function defined in Section 4.2 that requires
a threshold for the distance ratio threshold (
c
) to be fixed in advance.