Information Technology Reference
In-Depth Information
Simulation results
Sum
1
0
1
1
01
00 1
Cout
0000
1
0
1
1
1
B
01 01 01 0
1
0
A
0
1
0
1
0
Cin
0
1
0
Figure
4.19.
Simulation results for the full adder.
increase in significance, a larger number of clock cycles are introduced in order to
synchronize the arrival of the input with the carry of the preceding adder.
The layout of the 4-bit adder is shown in Figure 4.21.
The overall latency can be obtained by considering the critical path from one
of the inputs of the 1st adder to the carry output of the nth adder. Since the carry
output of a QCA full adder requires 1 clock cycle to complete, the overall latency
for the n-bit adder will be n clock cycles. The advantage of the QCA adder is that it
is inherently pipelined. As a result, we can feed new inputs into the adder every
clock cycle. When the pipeline is full, a new output will be available every clock
cycle independent of the depth of the pipeline.
An n-bit QCA carry-look-ahead adder can be expressed as
C
i
¼
G
i
þ
P
i
G
i
1
þ
P
i
P
i
1
G
i
2
þþ
P
i
P
1
C
0
¼
G
i
þ
P
i
ð
G
i
1
þ
P
i
1
ð þ ð
G
1
þ
P
1
C
0
ÞÞÞ
S
i
¼
C
i
1
P
i
C
i
1
P
i
þ
C
i
1
P
i
;
where
G
i
¼
A
i
B
i
;
P
i
¼
A
i
B
i
¼
A
i
B
i
þ
A
i
B
i
:
Due to the limitation of QCA to two-input AND and OR gates, the critical
path of a 4-bit carry-look-ahead adder consists of 10 majority gates as shown in
Figure 4.22. Therefore, the best case latency of this architecture is estimated at five
clock cycles.



























































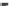

Search WWH ::

Custom Search