Hardware Reference
In-Depth Information
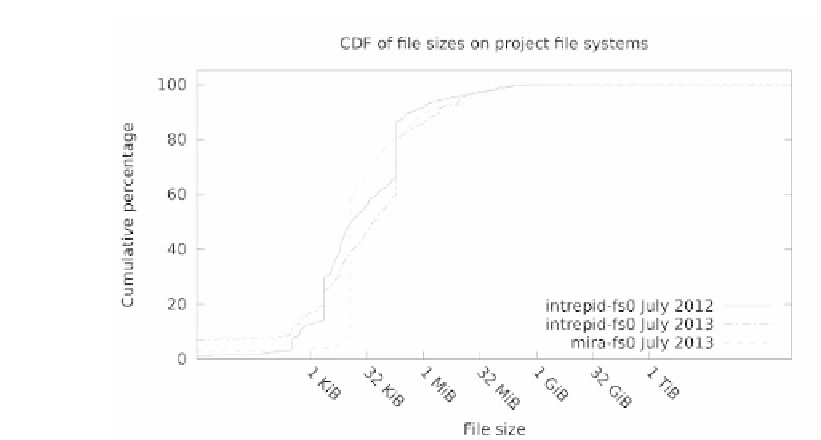
FIGURE 4.5: The cumulative distribution of file sizes on ALCF project file
systems.
to support large files well, although a workload of a lot of simultaneous file
I/O will generally work because all LUNs will still be utilized.
4.5.1 Case Studies
In 2010, ALCF deployed an I/O profiling tool named Darshan (see Chap-
ter 27), which is lightweight enough to be used in continuous operations. Ap-
plications compiled after ALCF deployed this tool would automatically pick
up the Darshan intercept libraries and began generating log files with statisti-
cal information about the I/O of that application. They analyzed about three
months of data collected to examine what type of I/O was being done at this
time and published the findings in Carns et al. [4]. In this study, they instru-
mented about 30% of the total core hours that ran during those three months.
During that study, Carns et al. looked at common I/O profiles for various
applications. They found that the file-per-rank model is the most popular
method for I/O. This model will utilize all the I/O node resources but will
only scale up well to about 8192 nodes. At this point, metadata overhead
for creating files starts becoming significant. This can be partly mitigated by
pre-creating unique directories for each file before the application run. This
reduces the serialization at the directory level when creating files. Scaling
beyond eight racks typically requires an application to start using shared files.
Either a single shared file may be used or a number of shared files. Shared
files are best handled using some form of aggregation and coordination like
that provided by MPI-IO (or libraries derived on top of it). The MPI ranks