Hardware Reference
In-Depth Information
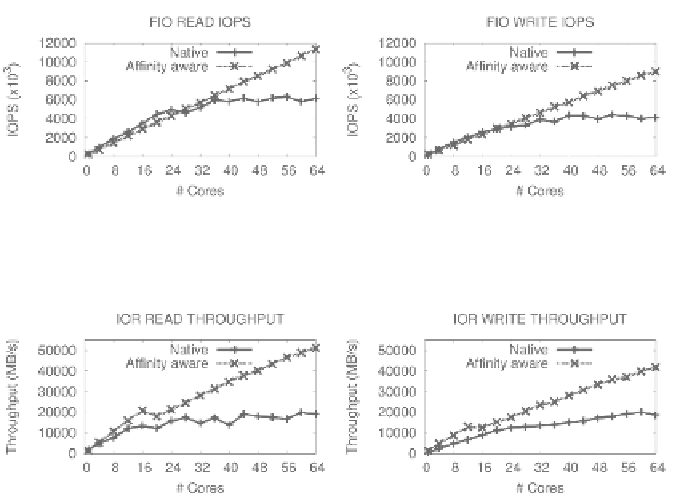
FIGURE 32.2: FIO read and write IOPS (4-KB random requests) of native
with and without proper placement in a 64-core machine.
FIGURE 32.3: IOR read and write throughput (4-KB requests) of native with
and without proper placement in a 64-core machine.
memory access overhead compared to smaller-scale systems. The same effect
is visible in this system as well, especially when more than one socket is shared
by application threads.
One approach to resolve this problem is to collocate threads and buffers
used for I/O. However, policies used should not interfere with the CPU's
scheduler policy to spread active threads over all server resources. Current
system software lacks mechanisms and policies to achieve this goal in the I/O
path transparently.
As a proof-of-concept, the I/O path redesign using custom Linux kernel
modules addresses the NUMA effects. A custom file system provides hints
to the CPU scheduler, and a DRAM cache creates separate memory pools to
cache pending I/O. The file system and the cache assign CPU cores and mem-
ory buffers from a single socket to application threads. Figures 32.2 and 32.3
show that custom I/O stacks are able to improve I/O throughput up to 84%
for random reads, 118% for random writes, 167% for sequential reads, and
123% for sequential writes.
32.4.2 Improving I/O Caching Eciency
Given the rate of data growth, modern applications tend to access larger
amounts of persistent storage. Therefore, the eciency of I/O caching is