Hardware Reference
In-Depth Information
to allow for a higher degree of isolation between independent streams of I/O
requests at all layers. For instance, I/O requests originating from different
contexts should be kept separate while traversing the I/O hierarchy, to avoid
generating mixed I/O patterns.
32.4 Challenges and Solutions
This section discusses an initial approach to improve the current I/O path
with respect to each problem listed in Section 32.3.
32.4.1 NUMA Eects
At present, a typical server implements a non-uniform memory architecture
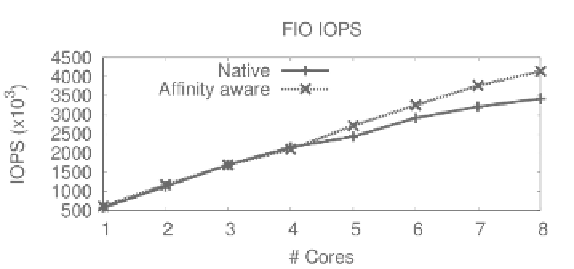
with at least two NUMA nodes. The results of running a flexible I/O (FIO)
tester [3] on a standard 8-core Intel machine with two sockets and relatively
uniform memory accesses is shown in Figure 32.1. The workload used consists
of 4-KB random read requests with one to eight application threads. The
two curves correspond to two runs: one that takes into account the anity
between threads and the memory they allocate, and a base execution that does
not. After four application threads, where both system sockets are occupied
with threads, the performance of the base execution deteriorates up to 21%
compared to the one that takes anity into account.
Figures 32.2 and 32.3 display results for both FIO and interleaved-or-
random benchmarking (IOR) [8], an MPI-based benchmark that emulates
checkpoint patterns on a 64-core AMD server with eight NUMA nodes or-
ganized in four sockets. This system exhibits pronounced non-uniformity in
FIGURE 32.1: FIO read IOPS (4-KB random requests) of native (XFS file
system) with and without proper placement. Performance of the base execu-
tion deteriorates by at most 21%.