Hardware Reference
In-Depth Information
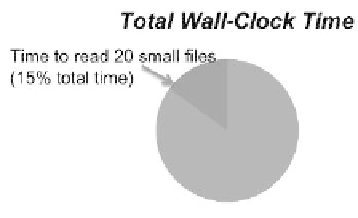
FIGURE 24.5: A job spent 15% of wall time reading 20 small input files.
24.5.1.2
Reading Small Input Files from Every Rank
In the second use case, an application using over 50,000 compute cores
is reading 20 small input files of around 1 KB each. This results in a large
amount time spent in opening the files as each of the 50,000 cores opens each
of the 20 input files. The result is that 15% of total application wall-clock time
is spent reading the 20 input files.
The user was advised to instead have a single MPI task open up each of the
20 input files and broadcast the contents of the file to the other 50,000 tasks.
24.5.1.3
Using the Wrong File System
In the last case, a user is spending a large (33%) of wall-clock time writing
a small amount of I/O. As the Darshan results show, the application wrote
only 640 MB, but achieved a rate of only 110 KB/s and spent 33% of time in
I/O. On further investigation using more detailed Darshan logs, NERSC staff
found the application was writing a file using 40,000 cores using the MPI-IO
interface to the NERSC home file system. The home file system at NERSC is
not configured for high-bandwidth I/O and is instead optimized for compiling
the applications. The user was advised to instead write the output file to the
larger \scratch" Lustre [8] le system. The Figure 24.6, shows the dramatic
improvement when the user switched to a high performing file system. The
FIGURE 24.6: Using the wrong file system can greatly impact the job perfor-
mance.