Hardware Reference
In-Depth Information
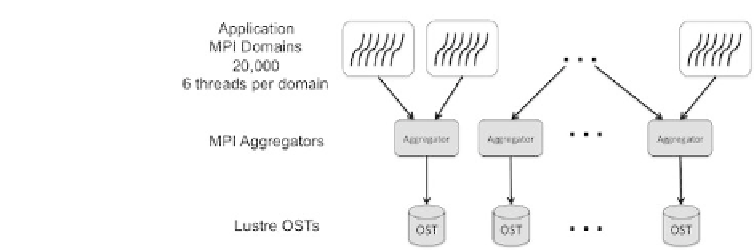
FIGURE 19.1: Configuration of the VPIC simulation using MPI and OpenMP
threads for computation. Parallel I/O uses MPI-IO in collective buffering
mode and the Lustre parallel file system.
flexibility and complexity in supporting arbitrary data models for ease of use
with a specific, particle-based data model.
Using a small set of H5Part API calls, parallel HDF5 I/O was quickly
integrated into the VPIC codebase. The simple H5Part interface for writing
VPIC particle data is outlined in the following lines of code:
h5pf=H5PartOpenFileParallel(fname,H5PART_WRITE|
H5PART_FS_LUSTRE,MPI_COMM_WORLD);
H5PartSetStep(h5pf,step);
H5PartSetNumParticlesStrided(h5pf,np_local,8);
H5PartWriteDataFloat32(h5pf,"dX",Pf);
H5PartWriteDataFloat32(h5pf,"dY",Pf+1);
H5PartWriteDataFloat32(h5pf,"dZ",Pf+2);
H5PartWriteDataInt32 (h5pf,"i",Pi+3);
H5PartWriteDataFloat32(h5pf,"Ux",Pf+4);
H5PartWriteDataFloat32(h5pf,"Uy",Pf+5);
H5PartWriteDataFloat32(h5pf,"Uz",Pf+6);
H5PartWriteDataFloat32(h5pf,"q",Pf+7);
H5PartCloseFile(h5pf);
The H5Part interface opens the particle file and sets up the at-
tributes, such as the timestep information and the number of particles. The
H5PartWrite
() calls wrap the internal HDF5 data writing calls.
The H5Part interface opens the file with MPI-I/O collective buffering and
Lustre optimizations enabled. Collective buffering breaks the parallel I/O op-
erations into two stages. The first stage uses a subset of MPI tasks to ag-
gregate the data into buffers, and the aggregator tasks then write data to
the I/O servers. With this strategy, fewer nodes communicate with the I/O
nodes, which reduces contention. The Lustre-aware implementation of Cray
MPI-I/O sets the number of aggregators equal to the striping factor such that
the stripe-sized chunks do not require padding to achieve stripe alignment
[4]. Because of the way Lustre is designed, stripe alignment is a key factor in
achieving optimal performance.