Information Technology Reference
In-Depth Information
the method uses a disk-based data structure and does not impose limitations on
the input trace size. Using the tree-based structures, the history database also
offers a fast query response time (O(log n)).
The remainder of the paper is organized as follows: after investigating the
background and related work, we present the architecture of the method, and
the details of its modules. Then, we discuss the implementation, visualization
and also evaluation and experimental results of the method. Finally, we conclude
and outline the possible future work.
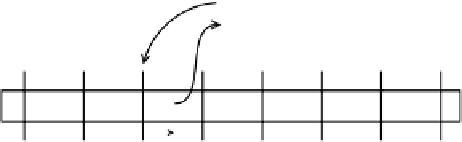
Fig. 1.
The process of resolving a query with the checkpoint method. (1) loading the
nearest previous checkpoint value, (2) replaying the trace events and updating the state
value, (3) returning the current state in response to the query.
2 Background
Modeling the system attributes and corresponding state values allows quickly
responding to queries about the system runtime behavior. In this research, we use
events and state values extracted from LTTng kernel tracer [DD08]. Colleagues
have shown [GDG
+
11, EJD12] examples of information and state values that
can be extracted from LTTng trace events. It would be technically possible for
LTTng to generate the state model at the same time as tracing, and save the
resulting information in the same trace events. However, this method may cause
problem: LTTng is presented as a high-performance tracer [DD08], with very
low impact on system behavior when tracing is enabled. The computation of the
state while tracing would increase the overhead.
To manage the state values, an inecient method could be rereading and re-
playing the trace, from the beginning to the requested query time, and updating
and extracting the required state values. Although this method can be used for
small traces and for specific usages (e.g. no space on disk for indexes), it is slow
and the delay increases with the position within the trace.
To improve the overall access time, some tools and viewers (e. g. LTTV and
TMF) use checkpoint method to store and manage the state vales, which consists
in saving in memory or disk at regular intervals (e.g., every 50,000 events or every
10 minutes of tracing), a complete snapshot of all system state values. When
users request the state value of a specific resource at any arbitrary time
t
of the
trace, the method loads the snapshot from the nearest previous checkpoint (
t
0
)
and starts rereading and replaying the trace events from that point and updates