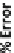Graphics Reference
In-Depth Information
Fig. 2.1
Typical evolution of % error when adjusting a supervised model. Underfitting is noticeable
in the
left side
of the figure
•
Overfitting
happens when the model is too tightly adjusted to data offering high
precision to known cases but behaving poorly with unseen data.
By using the whole data we may be aware of underfitting problems due to a low
performance of the model. Adjusting such a model to better fit the data may lead
to overfitting but the lack of unseen case makes impossible to notice this situation.
Please also note that taking this procedure to an extreme may lead to overfitting as
represented in Fig.
2.1
. According to Occam's Razor reasoning given two models
of similar generalization errors, one should prefer the simpler model over the more
complex model.
Overfitting may also appear due other reasons like noise as it may force the model
to be wrongly adjusted to false regions of the problem space. The lack of data will
also cause underfitting, as the inner measures followed by the ML algorithm can only
take into account known examples and their distribution in the space.
In order to control the model's performance, avoid overfitting and to have a gener-
alizable estimation of the quality of the model obtained several partitioning schemes
are introduced in the literature. The most common one is
k
-Fold Cross Validation
(
k
-FCV) [
17
]:
1. In
k
-FCV, the original data set is randomly partitioned into
k
equal size folds or
partitions
.
2. From the
k
partitions, one is retained as the validation data for testing the model,
and the remaining
k
1 subsamples are used to build the model.
3. As we have
k
partitions, the process is repeated
k
times with each of the
k
sub-
samples used exactly once as the validation data.
−
Finally the
k
results obtained from each one of the test partitions must be combined,
usually by averaging them, to produce a single value as depicted in Fig.
2.2
.This
procedure is widely used as it has been proved that these schemes asymptotically
converge to a stable value, which allows realistic comparisons between classifiers