Cryptography Reference
In-Depth Information
2.5.2 Subset Difference
We will next discuss the subset difference (SD) set system that outperforms
the complete subtree set system in terms of transmission overhead at the
expense of increasing the size of the set system. In fact the increase is such that
the number of keys required to be stored by each user become uneconomical
as it is linear in the number of users. This downside will be mitigated by a
non-trivial application of the key compression technique of Section
2.3.3
.
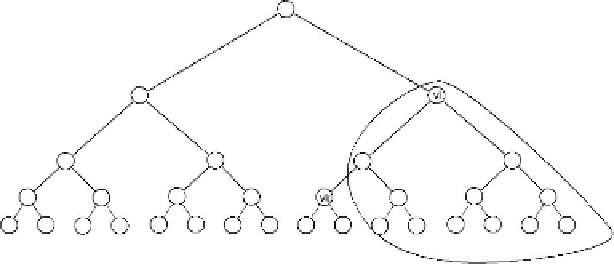
Fig. 2.11. The subset encoded by a pair of nodes (v
i
,v
k
) in the subset difference
method.
We consider again a binary tree whose leaves correspond to the receivers
in the user population [n] = {1,...,n} where n is a power of 2. A subset
S ∈ Φ
SD
= {S
j
}
j∈J
can be denoted by a pair of nodes j = (v
i
,v
k
) in the
binary tree where v
i
is an ancestor of v
k
. S
j
is the set of all leaves in the
subtree rooted at v
i
excluding the leaves in the subtree rooted at v
k
. See
Figure
2.11
for an example description of a subset.
Set system description in the KP framework.
The key poset of the subset difference method is, as expected, more com-
plex compared to the complete subtree set system. We refer reader to the
Figure
2.12
for a depiction of the key poset of SD method for 8 users.
Let J
SD
be the set of encodings of subsets in the set system Φ
SD
defined
over a set [n]. An element in J
SD
is a pair of binary strings so that the sum of
their length is less than or equal to log n. Recall that for the sake of simplicity
we assume that log n is an integer.
We define an index for each node in the binary tree in a top-down manner
similar indexing as in the complete subtree set system : the root of the binary
tree is encoded by , the index of a left child is constructed by appending '0'
to its parent's index while index of a right child is constructed by appending
'1' to its parent's index. An encoding j ∈J
SD
now is a pair of strings (L,R)