Cryptography Reference
In-Depth Information
The Karatsuba squaring process proceeds analogously to this and will not be
described in detail. For calling
kmul()
and
ksqr()
we make use of the functions
kmul_l()
and
ksqr_l()
, which are equipped with the standard interface.
Function:
Karatsuba multiplication and squaring
int kmul_l (CLINT a_l, CLINT b_l, CLINT p_l);
int ksqr_l (CLINT a_l, CLINT p_l);
Syntax:
a_l, b_l
(factors)
Input:
p_l
(product or square)
Output:
E_CLINT_OK
if all is ok
E_CLINT_OFL
if overflow
Return:
The implementation of the Karatsuba functions are contained in the source file
Extensive tests with these functions (on a Pentium III processor at 500 MHz
under Linux) have given best results when the nonrecursive multiplication
routine is called for a digit count under 40 (corresponding to 640 binary digits).
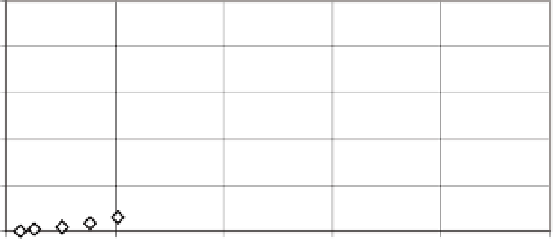
The computation time of our implementation appears in Figure 4-3).
50
40
mul_l
sqr_l
kmul_l
ksqr_l
30
20
10
0
0
1000
2000
3000
4000
5000
binary digits
Figure 4-3. CPU time for Karatsuba multiplication
We conclude from this overview what we expected, that between standard
multiplication and squaring there is a difference in performance of about 40
percent, and that for numbers of over 2000 binary digits a pronounced spread of
the measured times becomes noticeable, with the Karatsuba routine in the lead.
It is interesting to note that “normal” squaring
sqr_l()
is noticeably faster than
Karatsuba multiplication, and Karatsuba squaring
ksqr_l()
takes the lead only
above 3000 binary digits.