Biomedical Engineering Reference
In-Depth Information
G2M
S
G1
State index
FIGURE 14.4
Control definition points in a DNA histogram. The set of control definition
points that represent important transitions in a DNA histogram are shown as black circles.
defined the state or bin boundaries using cell age. How can we possibly measure these
bins from the data if we cannot measure cell age?
14.4.4.1 Control Definition Points Let us keep our simple DNA example to see
how this is done. Suppose we add to our state model a set of key inflection points
called control definition points (see Figure 14.4, y-axisisrelativeintensity)that
define the important transitions in DNA as the cell progresses along the cell cycle.
For the moment, assume that we have some magical way of associating an event
with one of the states on the x-axis. Initially, these control definition points are
positioned exactly in the right locations such that all the events are distributed
equally for all the states (Figure 14.5a, bottom plot). Even though the probability is
equal for all states, there still will be counting error that accounts for the chop in the
frequency data.
14.4.4.2 Importance of the State Frequency Distribution What happens if we
move the second control definition point to the left and then let the model reclassify
the data (see Figure 14.5b). Since there are now too few states to distribute the G1
events, the average number of events in this region is higher than it should be. In
contrast, there now are toomany states to distribute the S events so their average is less
than it should be. The more we move the control definition point from its ideal
location, the greater the disturbance in the state frequencies. If we move the second
control definition point up or down (not shown), it disturbs the classification system so
it no longer matches the data. Again, the result is a disturbance in the state frequencies.
14.4.4.3 Searching for Uniformity Suppose we had an accurate method of
quantifying how uniform the state frequencies were. We could then find the
control definition point locations that minimize this value. There are a number of
minimizationmethods that will do this for us [10, 11]. When these algorithms find this
minimum value, we have a solution to the problem. We have calculated our
probability state axis from the data.


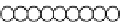







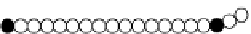





Search WWH ::

Custom Search