Biomedical Engineering Reference
In-Depth Information
which create a local subset of PubMed data by capturing the native field definitions, such as author
name, publication title, and MESH keywords. However, these products don't support the automatic
integration of structure and sequence data with functional data. Their support for text mining of the
data within a document is limited to simple user-directed keyword search.
The most advanced NLP systems work at the semantic level—the analysis of how meaning is created
by the use and interrelationships of words, phrases, and sentences in a sentence. Unlike a typical
search engine, these advanced systems attempt to automatically populate a database with, for
example, functional genomic and proteomic data relevant to a specific gene, protein, or disease,
including rules and trends not explicitly stated or defined in the documents. These systems, which
represent the leading edge of NLP R&D, are less reliable than systems based on keyword extraction
and distribution techniques in that they sometimes formulate incorrect rules and trends, resulting in
erroneous search results.
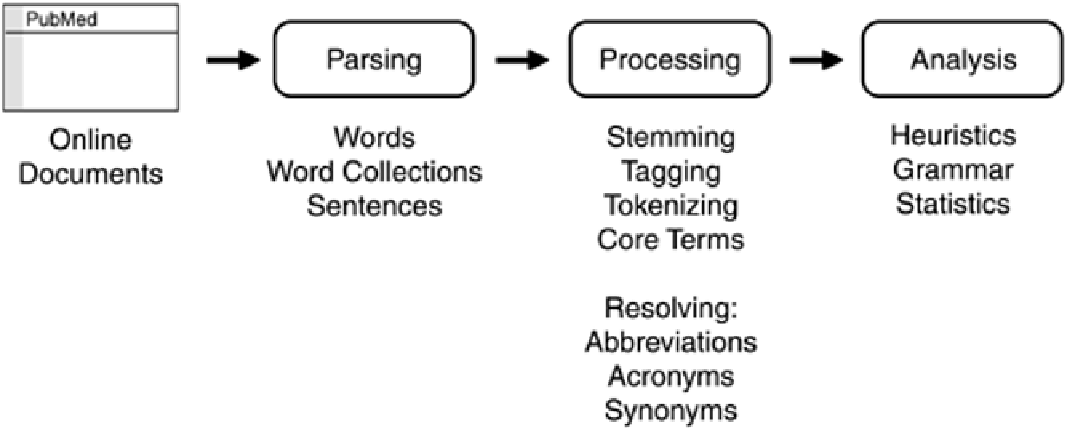
Regardless of the level of NLP, most systems follow the basic process outlined in
Figure 7-16
. Online
documents are first parsed into words, word collections, or sentences, depending on the NLP method
used. The simplest systems simply look at individual words, whereas systems that support mining of
document clusters focus on word collections to establish context. The most advanced NLP systems,
which attempt to extract meaning from words and word order, parse the documents at the sentence
level.
Figure 7-16. The NLP Process.
The processing phase of NLP involves one or more of a variety of the following techniques:
Stemming
— Identifying the stem of each word. For example, "hybridized", "hybridizing",
and "hybridization" would be stemmed to "hybrid". As a result, the analysis phase of the NLP
process has to deal with only the stem of each word, and not every possible permutation.
l
Tagging
— Identifying the part of speech represented by each word, such as noun, verb, or
adjective.
l
Tokenizing
— Segmenting sentences into words and phrases. This process determines which
words should be retained as phrases, and which ones should be segmented into individual
words. For example, "Type II Diabetes" should be retained as a word phrase, whereas "A
patient with diabetes" would be segmented into four separate words.
l
Core Terms
— Significant terms, such as protein names and experimental method names,
are identified, based on a dictionary of core terms. A related process is ignoring insignificant
words, such as "the", "and", and "a".
l
Resolving Abbreviations, Acronyms, and Synonyms
— Replacing abbreviations with the
words they represent, and resolving acronyms and synonyms to a controlled vocabulary. For
example, "DM" and "Diabetes Mellitus" could be resolved to "Type II Diabetes", depending on
the controlled vocabulary.
l