Biomedical Engineering Reference
In-Depth Information
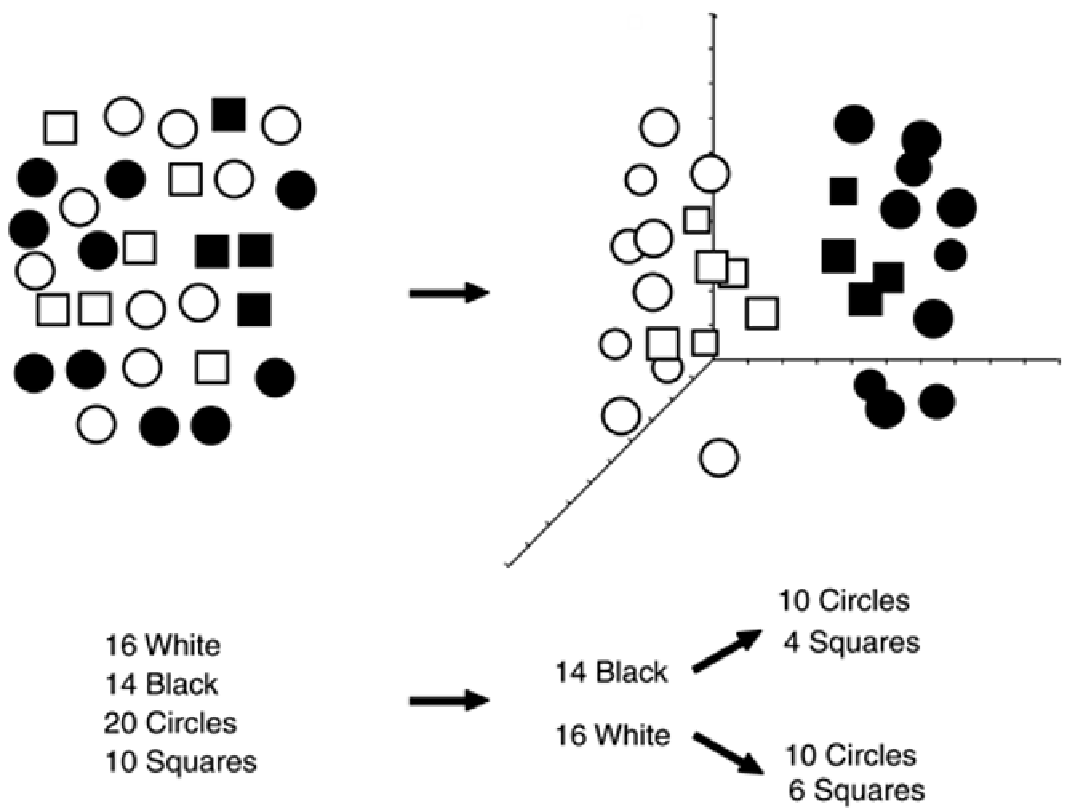
Figure 7-7. Induction-Based Classification. Using changes in entropy (a
measure of disorder) as an organizational heuristic, the induction algorithm
divides the unorganized data (top left) first by color and then by shape.
The alternative, bifurcating the circles and squares initially by shape would have resulted in a split of
10 to 20, which is less than the spread (increase in entropy) associated with a 14-to-16 split. In a
typical bioinfomatics data-mining problem, there may be 10 or more attributes to consider, according
to entropy change or some other driving heuristic.
Genetic Algorithms
Genetic algorithms are based on evolutionary principles wherein a particular function or definition
that best fits the constraints of an environment survives to the next generation, and the other
functions are eliminated. This iterative process continues indefinitely, allowing the algorithm to adapt
dynamically to the environment as needed. Genetic algorithms evaluate a large number of solutions
to a problem that are generated at random. The members of the solution population with the highest
fitness scores are allowed to "mate" with crossovers and mutations, creating the next generation.
Figure 7-8
illustrates the typical operation of a genetic operation. In this example, the possible
solutions to a problem defined by the fitness function are represented by bit strings. Each bit
represents the presence or absence of some quality that is mapped to the real-world solution. If
there is a need to represent gradations of quantities, then integers or floating-point variables could
be used instead of bit strings. However, in this example, 12 bits are used to represent the problem
matrix.