Cryptography Reference
In-Depth Information
There are two ways to specify a permutation, the first by equations linking
addresses before and after permutation, the second by a
look-up table
providing
the correspondence between addresses. The first is preferable from the point
of view of simplicity in the specification of the turbo code (standardization
committees are sensitive to this aspect) but the second can lead to better results
since the degree of freedom is generally larger when designing the permutation.
Regular permutation
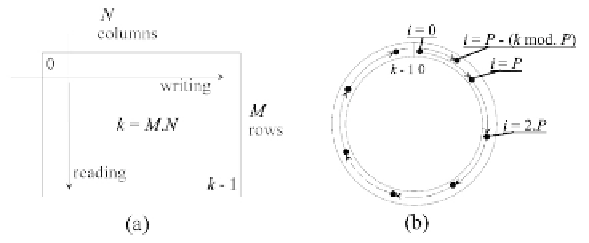
The point of departure when designing interleaving is regular permutation,
which is described in Figure 7.5 in two different forms. The first assumes that the
block containing
k
bits can be organized as a table of
M
rows and
N
columns.
The interleaving then involves writing the data in an
ad hoc
memory, row by
row, and reading them column by column (Figure 7.5(a)). The second applies
without any hypothesis about the value of
k
. After writing the data in a linear
memory (address
i
,
0
≤
i
≤
k
−
1
), the block is assimilated to a circle, the two
extremities (
i
=0
and
i
=
k
1
) then being adjacent (Figure 7.5(b)). The
binary data are then extracted in such a way that the
j
-th datum read has been
previously written in position
i
,withvalue:
−
i
=Π(
j
)=
Pj
+
i
0
mod
k
(7.4)
where
P
is a prime integer with
k
and
i
0
is the index of departure
1
.
Figure 7.5 - Regular permutation in rectangular (a) and circular (b) form.
For circular permutation, let us define the accumulated spatial distance
S
(
j
1
,j
2
)
as the sum of the two spatial distances separating two bits, before
and after permutation, whose reading indices are
j
1
and
j
2
:
S
(
j
1
,j
2
)=
f
(
j
1
,j
2
)+
f
(Π(
j
1
)
,
Π(
j
2
))
(7.5)
1
The permutation can, of course, be defined in a reciprocal form, that is,
j
function of
i
.It
is a convention that is to be adopted once and for all, and the one that we have chosen is
compatible with most standardized turbo codes.