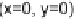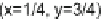Graphics Reference
In-Depth Information
Fig. 10.9
Interpolation process for a pixel at a fractional location x
D
1=4; y
D
3=4
Table 10.5
Example costs for interpolating a block of pixels
Block type
Generic
Y64 64
Y16 16
U4x4
Parameters Block size
w
h
64
64
16
16
4
4
Filter size
n
C
1 taps
8 taps
8 taps
4 taps
Costs
Reference pixels
.
w
C
n/
.h
C
n/ 71
71 (23 %) 23
23 (106 %) 7
7 (206 %)
Horizontal interps.
w
.h
C
n/
64
71 (11 %) 16
23 (43 %)
4
7 (75 %)
8 (0 %)
Values in brackets denote overhead over the block size. Costs are for uni-prediction only. For
bi-prediction, all the costs are doubled
Vertical interps.
w
h
64
64 (0 %)
16
16 (0 %)
8
a block of pixels, we see that smaller pixel blocks have a proportionately higher
overhead in the number of reference pixels and number of horizontal interpolations.
To reduce the worst case overhead, 4
4 PUs are not allowed by the standard and
8
4=4
8 PUs are allowed to use only uni-prediction.
Compared to H.264/AVC, HEVC uses
1. Larger PUs which require fewer interpolations per pixel but more on-chip SRAM
2. More varied PU sizes which increase complexity of control logic
3. Longer interpolation filters which require more datapath logic and more refer-
ence pixels
Reference frames may be stored in off-chip DRAM for HD and larger picture
sizes, or in on-chip SRAM for smaller sizes. At a PU level, it is observed that
reference pixels of adjacent PUs have significant overlap. Due to this spatial locality,
fetching the reference pixels into a motion-compensation (MC) cache helps reduce
the latency and power required to access external DRAM and large on-chip SRAMs.
Considering this, a top-level architecture (showing only the data-path) for an HEVC
inter-prediction engine would look like Fig.
10.10
.
The Dispatch module generates the position and size of the reference pixel block
according to the decoded motion vectors (MVs). The MC Cache will send read
requests to reference frame buffer over the direct-memory-access (DMA) bus for
cache misses. When all the reference pixels are present in the MC cache, the Fetch
module will fetch them from the cache for the 2-D Filter module. Note that it could
take many cycles to get data from DMA bus, due to latencies of bus arbiters, DRAM
controller, and DRAM Precharge/Activate operations.